源码解析-LinkedHashMap
# 概述
LinkedHashMap 是HashMap的子类,在HashMap已有的基础功能上又实现了一些额外的特性:迭代的时候可以保持插入的顺序或者访问的顺序。比如 put的顺序是k1、k2、k3,那么在迭代的时候也会保持k1、k2、k3的顺序。LinkedHashMap实现保持插入顺序是因为额外维护了一个Node节点的双向链表,简单图示如下,下面将从源码角度去解释下原理。
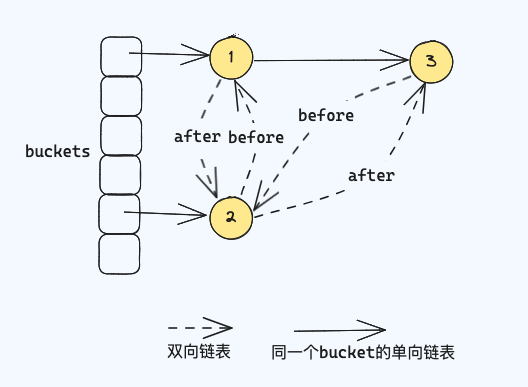
# 构造函数
/**
* The head (eldest) of the doubly linked list.
双向链表的头部
*/
transient LinkedHashMap.Entry<K,V> head;
/**
* The tail (youngest) of the doubly linked list.
双向链表的尾部
*/
transient LinkedHashMap.Entry<K,V> tail;
/**
* The iteration ordering method for this linked hash map: <tt>true</tt>
* for access-order, <tt>false</tt> for insertion-order.
*
* 通过该变量控制linkedHashMap的访问顺序,是插入顺序还是访问顺序
*/
final boolean accessOrder;
//LinkedHashMap内部自己的Entry节点,在HashMap的Node节点上扩展成双向节点,引用了前置节点和后置节点
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
accessOrder = false;
}
public LinkedHashMap(int initialCapacity) {
super(initialCapacity);
accessOrder = false;
}
public LinkedHashMap() {
super();
accessOrder = false;
}
public LinkedHashMap(Map<? extends K, ? extends V> m) {
super();
accessOrder = false;
putMapEntries(m, false);
}
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
可以看到LinkedHashMap的构造函数跟HashMap本身没有太大的区别,新增的参数accessOrder是控制LinkedHashMap的迭代顺序是访问顺序还是元素的插入顺序,顺便为了更方便的操作双向链表,新增了双向链表的head和tail节点。
# 方法解析
# put()
LinkedHashMap的put方法完全沿用HashMap的put方法,区别在于通过继承的方式在HashMap的基础上扩展了一些方法。我们简单来复习HashMap的put方法。(基于jdk1.8)
//完全是HashMap的put方法,省略部分代码
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
//如果Map第一次存数据
//省略code
......
if ((p = tab[i = (n - 1) & hash]) == null)
//对应buckets[index]上没有数据,也就是存入的node节点是buckets[index]上的第一个数据
//省略code
......
else {
//发生了hash冲突,在已有链表上寻找是否已经存在key
//省略code
......
// e != null的含义是 在冲突的链表上已经存在的这次要存储的key
if (e != null) {
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
//处理 节点访问后的动作 !!
afterNodeAccess(e);
return oldValue;
}
}
//走到这里 就可以确认key在已有的HashMap中是不存在的
++modCount;
//容量不足需要扩容数组
if (++size > threshold)
resize();
//处理 节点插入后的动作
afterNodeInsertion(evict);
return null;
}
// HashMap关于 这2个方法的实现全部是空的
void afterNodeAccess(Node<K,V> p) { }
void afterNodeInsertion(boolean evict) { }
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
重点就是 在HashMap中对于afterNodeAccess和afterNodeInsertion 两个方法全做了空处理,但是在LinkedHashMap中是对两个方法有实现了,这个也成为了LinkedHashMap特性的关键点,我们来看下LinkedHashMap的两个方法的具体实现。
/**
* 将访问过的节点移动到 LinkedHashMap 的末尾。
* accessOrder = true表示 按照访问顺序组织 LinkedHashMap的双向链表
* @param e 当前访问的节点
*/
void afterNodeAccess(Node<K,V> e) {
// LinkedHashMap 双向链表的尾部 last
LinkedHashMap.Entry<K,V> last;
// 如果 accessOrder 为 true 并且访问的节点 e 不是尾节点
if (accessOrder && (last = tail) != e) {
// 初始化变量 p 为访问的节点,b 为 p 的前一个节点,a 为 p 的后一个节点
LinkedHashMap.Entry<K,V> p = (LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
// 将访问的节点 p 的后一个节点设置为 null
p.after = null;
// 如果 p 的前直接点 b 为 null
if (b == null)
// 则将头节点设置为 a
head = a;
else
// 否则,将 b 的后置节点设置为 a
b.after = a;
// 如果 a 不为 null
if (a != null)
// 则将 a 的前置节点设置为 b
a.before = b;
else
// 否则,将双向链表的tail节点设置为 b
last = b;
// 如果tail节点为null
if (last == null)
// 则将head节点设置为 p
head = p;
else {
// 否则,将 p 的前置节点设置为tail节点
p.before = last;
// 并将tail节点的后置节点设置为 p
last.after = p;
}
// 将尾节点设置为 p
tail = p;
// 增加修改计数
++modCount;
}
//这里代码比较绕,主要是为了兼容各种情况,比如第一次head和tail都是空等等,大家可以debug以下。
//但是核心要表达的意思就是 当前需要check的节点会被放到整个双向链表的最后!!!
}
/**
* 在节点插入后可能进行移除操作。
*
* @param evict 是否需要移除最老的条目
*/
void afterNodeInsertion(boolean evict) {
// 定义一个 LinkedHashMap.Entry 类型的变量 first
LinkedHashMap.Entry<K,V> first;
// 如果 evict 为 true,且头节点存在,但是removeEldestEntry 在LinkedHashMap中默认返回false,也就是这个条件永远都不会成立
if (evict && (first = head) != null && removeEldestEntry(first)) {
// 获取头节点的 key
K key = first.key;
// 移除节点
removeNode(hash(key), key, null, false, true);
}
}
//linkedHashMap 判断是否要移除最老的entry默认返回false,但是方法是protect的,也就是可以子类继承LinkedHashMap去实现。
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
这里需要额外说明的就是afterNodeInsertion方法,实际上在LinkedHashMap中这个方法会执行但是 判断条件removeEldestEntry永远都不成立。那为什么LinkedHashMap 中存在这个方法呢? 答案是主要是为了扩展使用。
首先要理解afterNodeInsertion 整个方法的作用是:在插入一个新的key以后需要对key做逐出,也就是移除最老的节点。但是默认在LinkedHashMap中默认是不会删除任何key的,也就是会无限扩容,所以LinkedHashMap的removeEldestEntry默认是返回false。但是如果一个子类需要实现类似LRU缓存功能,保持一定的容量,超出容量就删除一些key,那就可以直接继承LinkedHashMap然后复写removeEldestEntry即可(这个就是LinkedHashMap可以轻易实现LRU缓存的原因)。
综上我们可以看到:
- 当accessOrder为true(保持访问顺序)的时候,通过复写HashMap的
afterNodeAccess实现了按照访问顺序把 所有节点串成一个双向链表。 - 当accessOrder为false(key的插入顺序)的时候,通过每个Entry新建的时候,指定了前驱和后继结点 来实现了插入的时候维持双向链表
# get()
//get方法的代码类似put方法,就不详细注释了,主要就是在访问到node节点的时候,如果是按照访问顺序维护双向链表,就调用afterNodeAccess方法
public V get(Object key) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return null;
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
2
3
4
5
6
7
8
9
# remove()
remove()方法其实类似于put()方法,也是在HashMap上做了扩展,扩展出来的方法是afterNodeRemoval,核心的逻辑就是:把双向链表中的已经被移除的节点去掉,详细就不细说了。
void afterNodeRemoval(Node<K,V> e) { // unlink
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.before = p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a == null)
tail = b;
else
a.before = b;
}
2
3
4
5
6
7
8
9
10
11
12
13
# 测试代码
public static void main(String[] args) {
System.out.println("--------HashMap 随机访问--------------");
HashMap<String, String> hashMap = new HashMap<>();
hashMap.put("k1", "v1");
hashMap.put("k2", "v2");
hashMap.put("k3", "v3");
hashMap.put("k11", "v11");
hashMap.put("k4", "v4");
//期望顺序是随机,不一定是k1 k2 k3 k11 k4
for (Map.Entry<String, String> entry : hashMap.entrySet()) {
System.out.println("key = " + entry.getKey() + ", value = " + entry.getValue());
}
System.out.println("--------LinkedHashMap 按照插入顺序--------------");
LinkedHashMap<String, String> linkedHashMap = new LinkedHashMap<>();
linkedHashMap.put("k1", "v1");
linkedHashMap.put("k2", "v2");
linkedHashMap.put("k3", "v3");
linkedHashMap.put("k11", "v11");
linkedHashMap.put("k4", "v4");
//期望顺序是 k1 k2 k3 k11 k4
for (Map.Entry<String, String> entry : linkedHashMap.entrySet()) {
System.out.println("key = " + entry.getKey() + ", value = " + entry.getValue());
}
System.out.println("--------LinkedHashMap 按照访问顺序顺序--------------");
LinkedHashMap<String, String> accessLinkedHashMap = new LinkedHashMap<>(16, 0.75f, true);
accessLinkedHashMap.put("k1", "v1");
accessLinkedHashMap.put("k2", "v2");
accessLinkedHashMap.put("k3", "v3");
accessLinkedHashMap.put("k11", "v11");
accessLinkedHashMap.put("k4", "v4");
accessLinkedHashMap.get("k1");
//期望顺序是 k2 k3 k11 k4 k1 (因为k1最后又被访问了一次)
for (Map.Entry<String, String> entry : accessLinkedHashMap.entrySet()) {
System.out.println("key = " + entry.getKey() + ", value = " + entry.getValue());
}
}
输出结果:
--------HashMap 随机访问--------------
key = k1, value = v1
key = k2, value = v2
key = k3, value = v3
key = k4, value = v4
key = k11, value = v11
--------LinkedHashMap 按照插入顺序--------------
key = k1, value = v1
key = k2, value = v2
key = k3, value = v3
key = k11, value = v11
key = k4, value = v4
--------LinkedHashMap 按照访问顺序顺序--------------
key = k2, value = v2
key = k3, value = v3
key = k11, value = v11
key = k4, value = v4
key = k1, value = v1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
# 总结
大家需要关注的LinkedHashMap特性
是HashMap的子类,通过覆写父类方法实现了 迭代的时候可以保持插入的顺序或者访问的顺序
通过继承LinkedHashMap,覆写
removeEldestEntry来实现一个简单的LRU