库存的超卖与少卖
# 前言
在电商交易系统中常见的一个考察点或者说是难点就在库存的处理上,库存处理在高并发场景下一般会遇到以下问题
- 超卖
- 少卖
下面就详细解释下如何解决库存系统重的超卖与少卖的问题
# 超卖
所谓超卖指的就是商品卖多了,正常我们处理商品库存扣减步骤是
- 查询库存是否足够
- 如果足够则扣减库存
- 如果不够则返回扣减失败
但是在高并发的情况下会存在以下问题
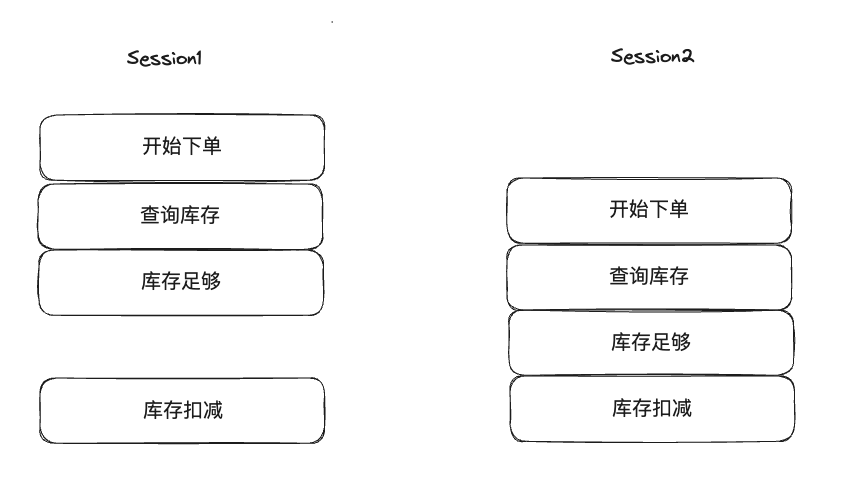
当有两个并发线程,同时查询库存,可以看到当session1查询完库存但是并未进行扣减之前,session2查到的库存数据是跟session1相同的,假设这时候库存只有1个了,当session1和session2同时执行库存扣减的时候就会发生库存被扣减到负数的情况,这就是超卖。
之所以会发生以上问题,主要是因为并发导致的,所以,解决超卖的问题本质上是解决并发问题。
以上问题,最终就是要实现库存扣减过程中的原子性和有序性。
- 原子性:库存查询、库存判断以及库存扣减动作,作为一个原子操作,过程中不会被打断,也不会有其他线程执行。
- 有序性:多个并发操作需要排队执行。
# 数据库实现库存扣减
使用数据库区实现库存扣减是最简单的易行的方案,但是次方案也存在诸多缺点。
在扣减过程中,想要保证原子性和有序性,我们可以采用加锁的方式,无论是悲观锁、还是乐观锁都可以实现的。
# 使用悲观锁实现
比如我们使用悲观锁实现的时候大致流程如下
START TRANSACTION;
-- 锁定特定商品的行
SELECT stock FROM inventory WHERE id = 1 FOR UPDATE;
-- 检查库存是否足够
UPDATE inventory
SET stock = stock - 1
WHERE id = 1 AND stock > 0;
COMMIT;
2
3
4
5
6
7
8
9
10
11
12
但是上面的SQL明显存在的问题是,SELECT FOR UPDATE 会导致数据库锁,从而导致很多请求被迫阻塞并且排队,那么如果并发请求量很大的话,就可能直接把数据库给拖垮了。
# 使用乐观锁实现
比如我们使用乐观锁实现的时候大致流程如下
START TRANSACTION;
-- 获取当前库存和版本号
SELECT stock, version FROM inventory WHERE id = 1;
-- 假设查询结果为 stock = 10, version = 1
-- 检查库存是否足够并更新库存和版本号
UPDATE inventory
SET stock = stock - 1, version = version + 1
WHERE product_id = 1 AND stock > 0 AND version = 1;
-- 检查更新是否成功
SELECT ROW_COUNT() AS affected_rows;
COMMIT;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
上面的SQL可以看出 UPDATE的时候针对 product_id = 1的数据行也存在热点更新的问题,也会导致数据库的行锁,从而导致请求的阻塞,最终拖垮数据库。
# 乐观锁变种
相对于乐观锁与悲观锁,其实还有办法可以把数据库的锁控制在更小的粒度上
START TRANSACTION;
-- 获取当前库存和版本号
SELECT stock, version FROM inventory WHERE id = 1;
-- 假设查询结果为 stock = 10, version = 1
-- 检查库存是否足够并更新库存和版本号
UPDATE inventory
SET stock = stock - n
WHERE product_id = 1 AND stock > n
COMMIT;
2
3
4
5
6
7
8
9
10
11
12
13
如果上述SQL可以执行成功的话,是可以确保库存余量大于等于0的,这就避免了超卖的发生。
但是这个方案本质上和乐观锁存在一样的问题:更新的热点,也就是在高并发的情况下多线程去扣减是一定发生阻塞,最终导致数据库雪崩的,优化的空间几乎没有(提升数据库配置)。
那么有没有更好的解决方案呢 ?
# Redis扣减
我们可以基于Redis做库存扣减的,借助Redis的单线程执行和Lua脚本执行的原子性来实现高并发的库存扣减
举例库存扣减如下:
local key = KEYS[1] -- 商品的键名
local amount = tonumber(ARGV[1]) -- 扣减的数量
-- 获取商品当前的库存量
local stock = tonumber(redis.call('get', key))
-- 检查库存是否足够
if stock and stock >= amount then
-- 减少库存并返回新的库存量
return redis.call('decrby', key, amount)
else
return "INSUFFICIENT STOCK"
end
2
3
4
5
6
7
8
9
10
11
12
13
14
先从Redis中取出当前的剩余库存,然后判断是否足够扣减,如果足够的话,就进行扣减,否则就返回库存不足。
因为lua脚本在执行过程中,可以避免被打断,并且redis执行的过程也是单线程的,所以在脚本中进行判断,再扣减,这个过程是可以避免并发的。所以也就可以实现前面我们说的原子性+有序性了。
并且Redis是一个高性能的分布式缓存,使用Lua脚本扣减库存的方案也非常的高效。
# 实际应用
在实际使用的场景中一般会结合以上两种方案来使用,也就是通过redis扣减来抗住高并发,同时设计一定的数据同步机制做数据库的扣减,最终达到数据的最终一致性。
举例来说:
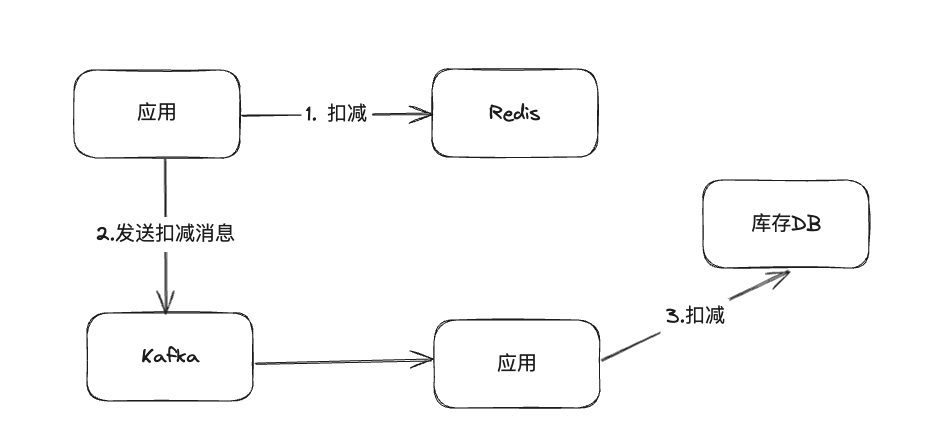
这样做,我们可以保证Redis中的数据和数据库中的数据的一个最终一致性。并且也能避免超卖的发生。
但是按照图上的流程,假设在发送kafka消息的时候失败了,那就会导致另外一个问题:少卖
# 少卖
假设在上面的流程中,执行redis扣减的步骤成功了,但是第二步发送kafka消息的步骤失败了,那就会导致redis执行了库存的扣减,但是数据库并未执行扣减,也就是实际的库存是大于redis中的库存的,那么带来的问题就是少卖
那么为了解决少卖的问题,一般解决方式就是引入数据对比的机制(对账)
# 对账
做过金融相关开发的同学应该对【对账】这个程序不陌生,简单来说就是要把实际发生的每一笔账以及相关的账号、订单各个领域的数据做交叉对比,从而保证数据不会错乱,也可以发现系统中潜在的问题或者漏洞bug。
那在扣减这个场景中,为了避免实际库存和redis中库存不一致,需要引入的就是类似于对账机制的数据对比机制。当然对账系统的设计本身就是一个宏达的命题,我们这里只简单的说一下,假设我们使用 订单数据源来和库存的数据做对比,步骤如下
- 监听每一笔订单的数据,并且记录其消耗库存
- 查询库存流水表 是否有对应的订单记录,并且和消耗库存是否对的上
- 或者每次有一笔订单数据生成 都去查一下 当前product的库存查看是否和redis库存对的上
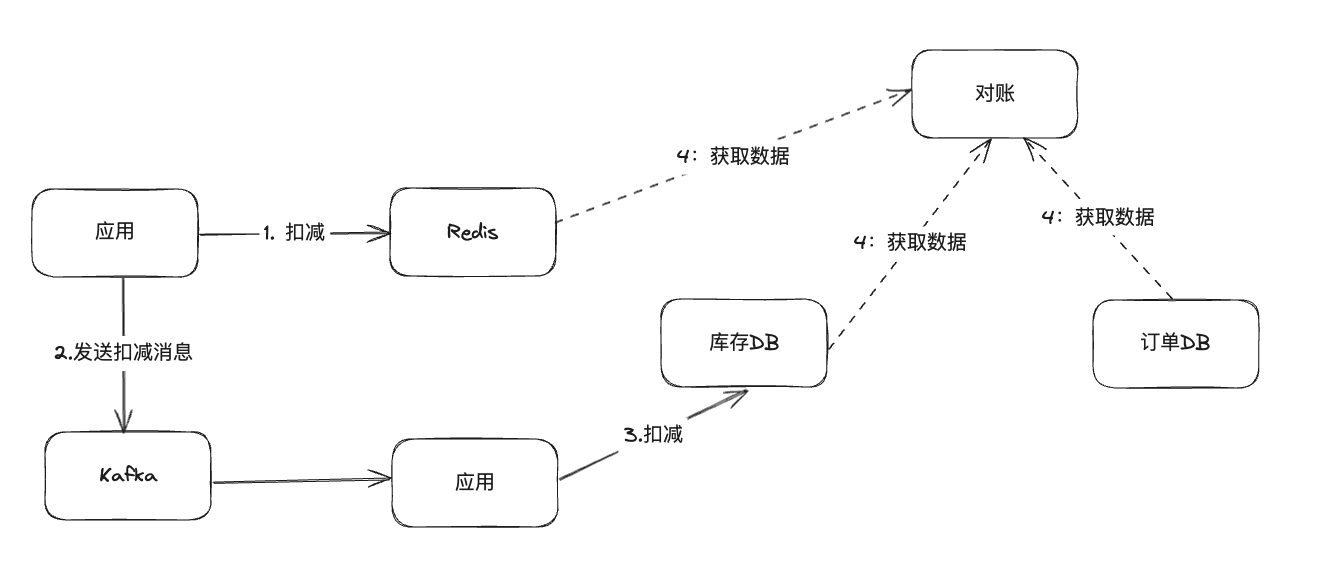
在这个场景中不管是使用订单表来交叉对比,还是直接不停的直接对比 redis和数据库,都可以立刻发现数据的不一致。
← 订单超时关闭