源码解析-HashMap原创
# 前言
HashMap是面试中被问到或者工作中使用到最常见的类了,几乎没有之一。所以本篇文章除了在源码解析的基础上,还会涉及到一些常见的对于HashMap的疑问,文章内容较长,希望看完能有所收获。
# 概述
在Java中保存数据有两种基本的数据结构:数组与链表。
数组的特点是:
- 寻址容易:数据在逻辑与物理上都是连续的,所以寻址比较容易(只需要从内存开始的地址即可计算出指定index的位置元素的内存地址)。
- 插入和删除比较困难(删除元素后需要做数据的移动,从而保证数据在物理内存上是连续的)
链表的特点正好跟数组相反:
- 寻址困难:物理内存不要求连续,所以寻找元素需要遍历整个链表
- 插入删除比较容易:因为不要求内存上数据连续,所以插入删除后不需要数据移动,并且链表节点通常保存上游或者下游节点
而HashMap的实现则最大化的利用了两者的优点:让查询和增删数据的平均时间复杂度接近O(1)
# 底层数据结构
HashMap 主要用来存放键值对,它基于哈希表的 Map 接口实现,是常用的 Java 集合之一,是非线程安全的。
# JDK1.7
哈希冲突的解决办法之一叫做链表法,就是将数组与链表结合在一起,将具有不同hash值的key放置在数组的不同位置,而相同的hash值的key则从数组的位置上引申出一个链表来进行存储,这样就发挥了数组与链表两者的优势,在JDK1.8之前,HashMap就是通过这种数据结构来存储数据的。
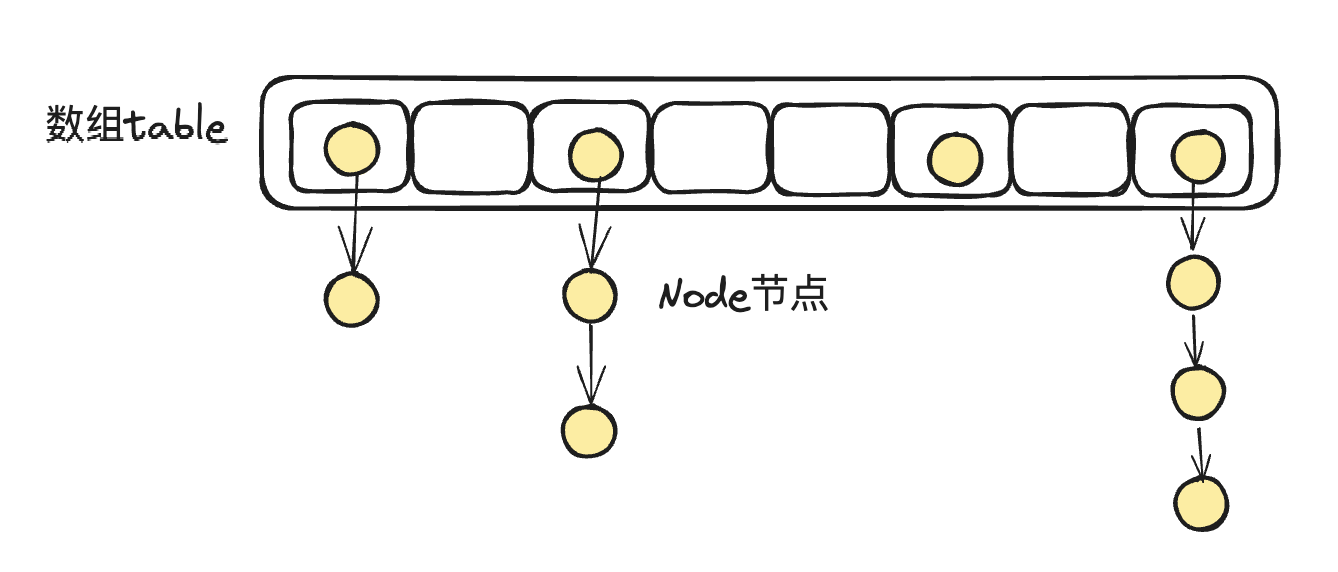
# JDK1.8
在JDK 1.8中为了解决因hash冲突导致某个链表长度过长,影响put和get的效率,引入了红黑树:即当链表长度超过 8 的时候,链表便会转为红黑树,另外,当链表长度小于 6 的时候,会从红黑树转为链表
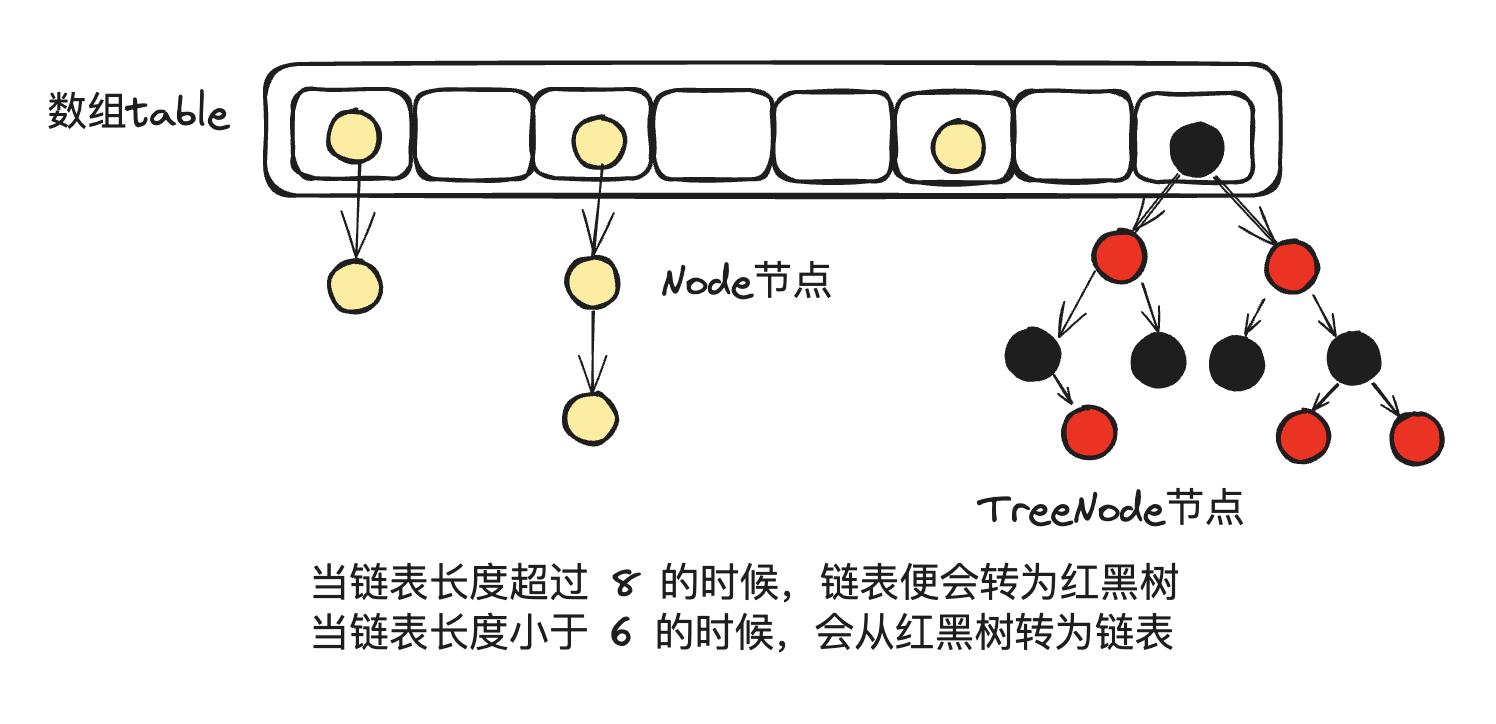
# 源码分析
# 构造函数
# jdk1.8
/**
* HashMap容量默认初始化的大小,16,必须是2的幂次方(方便位操作)
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
/**
* HashMap可以达到的最大容量,如果超出则使用该值,2^30 次方
*/
static final int MAXIMUM_CAPACITY = 1 << 30;
/**
* 负载系数:当前元素数量/容量 > DEFAULT_LOAD_FACTOR 则触发扩容
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
/**
* 当链表长度大于等于该值 则会转成红黑树
*/
static final int TREEIFY_THRESHOLD = 8;
/**
* 当红黑树上节点小于等于该值的时候 退化成链表
*/
static final int UNTREEIFY_THRESHOLD = 6;
/**
* The smallest table capacity for which bins may be treeified.
* (Otherwise the table is resized if too many nodes in a bin.)
* Should be at least 4 * TREEIFY_THRESHOLD to avoid conflicts
* between resizing and treeification thresholds.
* 允许线性表转换为红黑树的整个hashMap中元素数量的最小值,也就是只有HashMap中元素大于等于64才会触发树化
*/
static final int MIN_TREEIFY_CAPACITY = 64;
//指定初始化容量和负载因子
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
//初始化容量最大不会大于MAXIMUM_CAPACITY
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
/**
* Returns a power of two size for the given target capacity.
* 经过一系列的位运算最后返回比给定cap大的最小的2的次幂
* 比如cap=6,则返回8,cap=8,返回8,cap=12,返回16
*/
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
/**
* Constructs an empty <tt>HashMap</tt> with the specified initial
* capacity and the default load factor (0.75).
*
* @param initialCapacity the initial capacity.
* @throws IllegalArgumentException if the initial capacity is negative.
* 只指定初始化容量,使用默认的负载因子0.75
*/
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
/**
* Constructs an empty <tt>HashMap</tt> with the default initial capacity
* (16) and the default load factor (0.75).
* 没有任何初始化参数,默认容量16和负载因子0.75
*/
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
/**
* Constructs a new <tt>HashMap</tt> with the same mappings as the
* specified <tt>Map</tt>. The <tt>HashMap</tt> is created with
* default load factor (0.75) and an initial capacity sufficient to
* hold the mappings in the specified <tt>Map</tt>.
*
* @param m the map whose mappings are to be placed in this map
* @throws NullPointerException if the specified map is null
* 将给定的Map集合初始化到当前map
*/
public HashMap(Map<? extends K, ? extends V> m) {
this.loadFactor = DEFAULT_LOAD_FACTOR;
putMapEntries(m, false);
}
/**
* Implements Map.putAll and Map constructor.
*
* @param m the map
* @param evict false when initially constructing this map, else
* true (relayed to method afterNodeInsertion).
* 将已有map集合中数据全部put进新的map
*/
final void putMapEntries(Map<? extends K, ? extends V> m, boolean evict) {
int s = m.size();
if (s > 0) {
//当前map还未初始化
if (table == null) { // pre-size
//计算出目前需要放置多少个元素
float ft = ((float)s / loadFactor) + 1.0F;
int t = ((ft < (float)MAXIMUM_CAPACITY) ?
(int)ft : MAXIMUM_CAPACITY);
//threshold 表示 触发map resize的阈值,目前map还未初始化 threshold = 0
//如果 需要放置的元素 大于需要扩容的阈值,计算出当前map需要初始化的容量大小
if (t > threshold)
threshold = tableSizeFor(t);
}
//如果map已经初始化了(map的putAll方法也调用此方法),则判断新增的元素数量s 是否大于扩容阈值
//如果大于则提前扩容
else if (s > threshold)
//后面详解
resize();
//遍历map把map中每一个值放置到新的map中,这里需要注意,如果存在相同的key则会覆盖掉
for (Map.Entry<? extends K, ? extends V> e : m.entrySet()) {
K key = e.getKey();
V value = e.getValue();
//后面详解
putVal(hash(key), key, value, false, evict);
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
# Hash()方法
# jdk1.8
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
//put方法的求key的所在table的index位置的代码,n是table的长度 hash是key的hash值
if ((p = tab[i = (n - 1) & hash]) == null)
2
3
4
5
6
7
8
以上方法其实看起来比较简单,但是比较难理解整体就是三个步骤
- 获取key的hashCode(), hashCode是native方法,不同平台实现不同,赋值给变量h
h>>>16表示 无符号右移 16位置 (前面补0)- 把 h 和 h右移16位的值进行异或
对于任意给定的对象,只要它的hashCode()返回值相同,那么程序调用方法一所计算得到的Hash码值总是相同的。
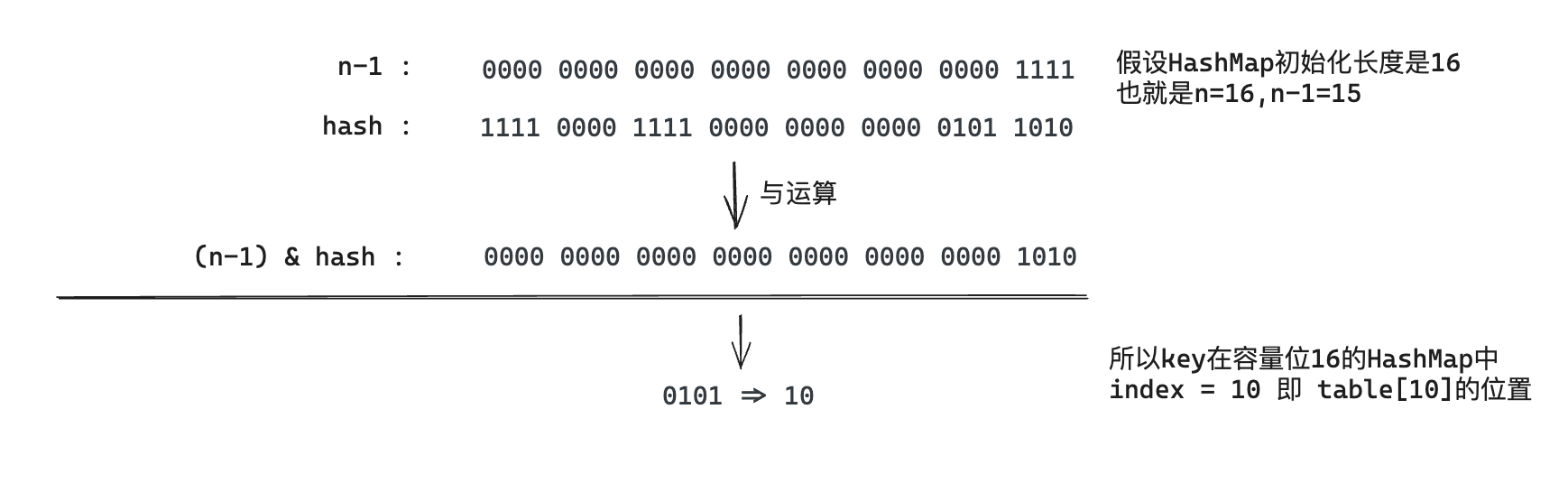
我们首先想到的就是把hash值对数组长度取模运算,这样一来,元素的分布相对来说是比较均匀的。但是,模运算的消耗还是比较大的,在HashMap中是这样做的:调用(n - 1) & hash来计算该对象应该保存在table数组的哪个索引处。
这个方法非常巧妙,它通过h & (table.length -1)来得到该对象的保存位,而HashMap底层数组的长度总是2的n次方,这是HashMap在速度上的优化。当length总是2的n次方时,h& (length-1)运算等价于对length取模,也就是h%length,但是&比%具有更高的效率。
在JDK1.8的实现中,优化了高位运算的算法,通过hashCode()的高16位异或低16位实现的:(h = k.hashCode()) ^ (h >>> 16),主要是从速度、功效、质量来考虑的,这么做可以在数组table的length比较小的时候,也能考虑到高低Bit都参与到Hash的计算中,同时不会有太大的开销。
下面举例说明下,n为table的长度。
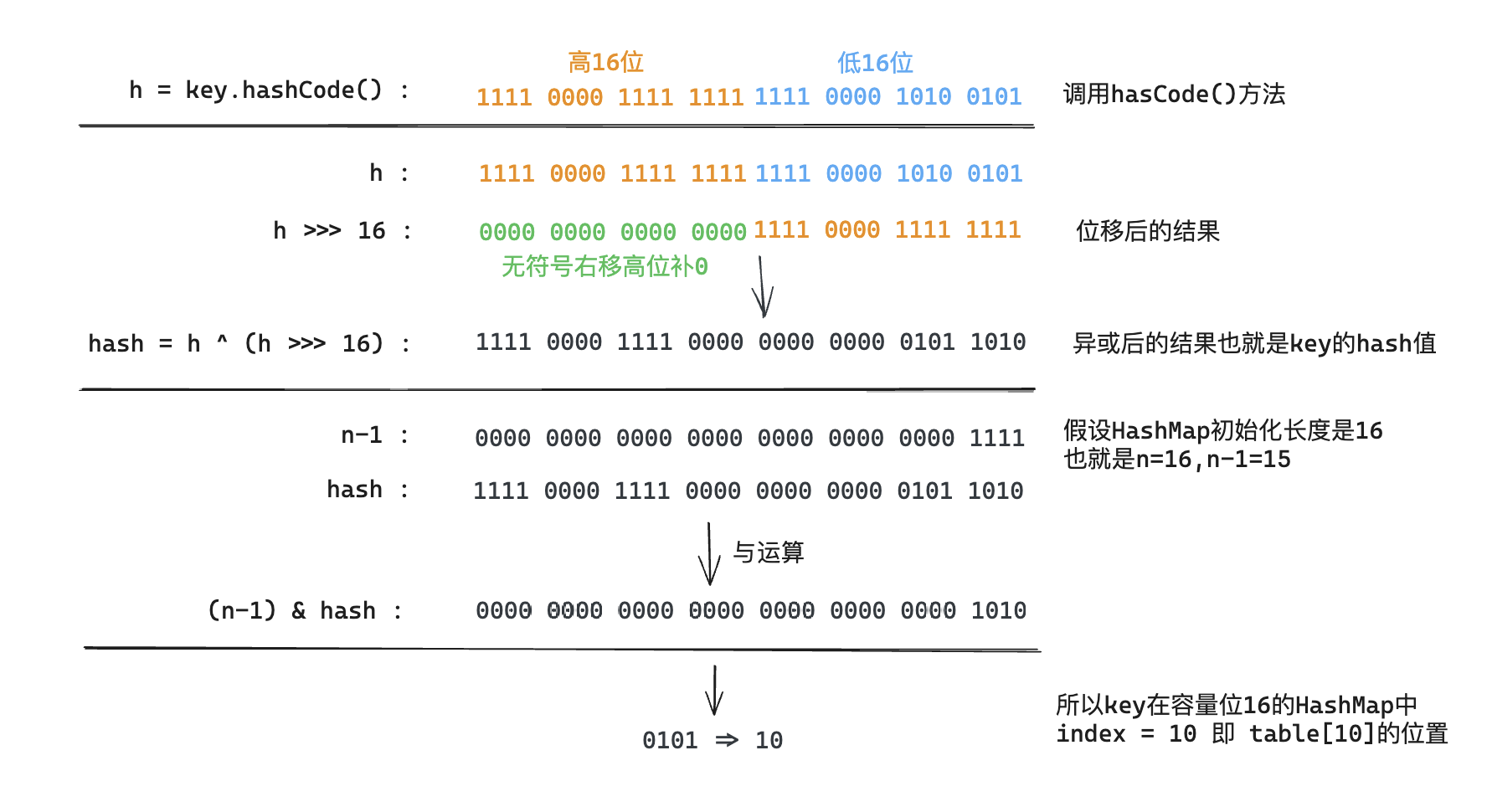
这里介绍jdk1.8的hash方法运算过程主要是为了后续 jdk1.8的resize方法做补充,在jdk1.8的扩容方法resize中核心利用了hash方法实现了快速获取扩容后key的index位置!!(很重要)
# put方法
# JDK1.8
put方法1.8源码如下
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
//计算出key的hash值
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
/**
* Implements Map.put and related methods.
*
* @param hash hash for key
* @param key the key
* @param value the value to put
* @param onlyIfAbsent if true, don't change existing value
* @param evict if false, the table is in creation mode.
* @return previous value, or null if none
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
//如果table为空,则直接调用resize()方法扩容
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
//1.根据hash值计算出key应该放在table的index值 i
//2.判断table[i]是否为空
//3.如果table[i]值为空,则直接把key,value包装成一个node节点放置到table[i]位置
tab[i] = newNode(hash, key, value, null);
else {
//如果table的对应index的位置存在值
Node<K,V> e; K k;
//特殊判断下 要存放的key是否跟table的index位置的首个node节点key相同
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
//如果相同,直接给e赋值p(p是table[i],表示当前hashmap中已经存在的node)
e = p;
else if (p instanceof TreeNode)
//如果p是一个树节点,说明table[i]位置的是一棵树,直接调用树的方法插入新的数据(后面会介绍)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
//最开始p是这个链表的头结点
//binCount是记个数表示当前遍历到的节点的index,比节点数量-1
for (int binCount = 0; ; ++binCount) {
//e节点表式p的next节点,如果为空,则表示遍历到了链表的最末尾
if ((e = p.next) == null) {
//把key value包装成一个新的node节点直接插入整条链表的尾部(尾插法)
p.next = newNode(hash, key, value, null);
// 判断节点数量 是否大于等于 树化的临界值TREEIFY_THRESHOLD
// binCount表示index所以跟TREEIFY_THRESHOLD比较的时候 需要 -1
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
//链表开始树化(后续介绍)
treeifyBin(tab, hash);
break;
}
//代码执行到这里说明没有遍历完整个链表
//在遍历链表期间需要每个值去判断是否已经存在相同的key,如果存在相同key直接跳出整个循环
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
//都不满足条件,把p赋值成当前的节点e,然后继续遍历链表
p = e;
}
}
//从上面代码可以看到,只有找到跟需要插入的key相同的value的节点,e才会被赋值(包括putTreeVal方法)
//所以这里的意思是 如果找到了跟当前key和value相同的节点
if (e != null) { // existing mapping for key
//把e节点的value记录下
V oldValue = e.value;
//如果满足参数条件或者oldValue为空,则使用新的value替换掉oldValue
if (!onlyIfAbsent || oldValue == null)
e.value = value;
//扩展方法,HashMap实现为空
afterNodeAccess(e);
//整个put方法返回就是 oldValue
return oldValue;
}
}
//次该次数+1
++modCount;
//整个HashMap中元素数量+1
//如果HashMap中元素数量大于 需要扩容的阈值(负载因子 * 总容量)
if (++size > threshold)
//HashMap扩容(在后面有分析)
resize();
//扩展方法 HashMap空实现
afterNodeInsertion(evict);
//如果HashMap中不存在要插入的key,默认返回的是null
return null;
}
//HashMap链表的节点,可以看到这个链表是个单向的链表
static class Node<K,V> implements Map.Entry<K,V> {
//节点的hash值
final int hash;
//节点的key
final K key;
//节点的value
V value;
//节点的下一个节点
Node<K,V> next;
}
/**
* 将链表 红黑树 化,了解即可,暂时还没面试那么变态 让撸这个代码
*/
final void treeifyBin(Node<K,V>[] tab, int hash) {
// n表示数组的长度,index表示计算得到的哈希值,e表示当前节点
int n, index;
Node<K,V> e;
// 如果数组为空或者长度小于树化的最小容量阈值,则进行扩容
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize();
// 如果数组长度大于等于树化的最小容量阈值,并且哈希位置存在节点
else if ((e = tab[index = (n - 1) & hash]) != null) {
// hd表示树化后的头节点,tl表示树化后的尾节点
TreeNode<K,V> hd = null, tl = null;
do {
// 将当前节点替换为树节点
TreeNode<K,V> p = replacementTreeNode(e, null);
// 如果尾节点为空,将当前树节点设置为头节点
if (tl == null)
hd = p;
else {
// 将当前树节点与尾节点连接起来
p.prev = tl;
tl.next = p;
}
// 更新尾节点为当前树节点
tl = p;
} while ((e = e.next) != null);
// 将树化后的头节点放回原来的位置
if ((tab[index] = hd) != null)
hd.treeify(tab);
}
}
//关于红黑树的插入大家了解即可,后续会在数据结构中详细介绍,暂时还没面试官那么变态让手撸代码
/**
* 将键值对插入树节点中。
*
* @param map HashMap 实例
* @param tab 节点数组
* @param h 键的哈希值
* @param k 键
* @param v 值
* @return 如果存在相同的键,则返回对应的节点;否则返回 null
*/
final TreeNode<K,V> putTreeVal(HashMap<K,V> map, Node<K,V>[] tab,
int h, K k, V v) {
// 用于存储键的类
Class<?> kc = null;
// 标记是否已经搜索过树
boolean searched = false;
// 获取树的根节点
TreeNode<K,V> root = (parent != null) ? root() : this;
// 循环遍历树节点
for (TreeNode<K,V> p = root;;) {
// dir用于表示插入位置的方向,ph用于存储节点的哈希值
int dir, ph;
// 用于存储节点的键
K pk;
// 比较节点的哈希值与要插入键的哈希值
if ((ph = p.hash) > h)
dir = -1; // 节点的哈希值大于要插入键的哈希值,插入位置在左子树
else if (ph < h)
dir = 1; // 节点的哈希值小于要插入键的哈希值,插入位置在右子树
else if ((pk = p.key) == k || (k != null && k.equals(pk)))
return p; // 键已存在,返回对应的节点
else if ((kc == null &&
(kc = comparableClassFor(k)) == null) ||
(dir = compareComparables(kc, k, pk)) == 0) {
// 如果还没有搜索过树
if (!searched) {
TreeNode<K,V> q, ch;
// 标记已经搜索过树
searched = true;
// 在子树中找到了相同的键,返回对应的节点
if (((ch = p.left) != null &&
(q = ch.find(h, k, kc)) != null) ||
((ch = p.right) != null &&
(q = ch.find(h, k, kc)) != null))
return q;
}
// 使用比较器进行比较
dir = tieBreakOrder(k, pk);
}
// 保存父节点
TreeNode<K,V> xp = p;
// 到达插入位置
if ((p = (dir <= 0) ? p.left : p.right) == null) {
// 保存父节点的下一个节点
Node<K,V> xpn = xp.next;
// 创建新的树节点
TreeNode<K,V> x = map.newTreeNode(h, k, v, xpn);
// 插入到左子树
if (dir <= 0)
xp.left = x;
// 插入到右子树
else
xp.right = x;
// 更新父节点的下一个节点
xp.next = x;
// 设置节点的父节点和前一个节点
x.parent = x.prev = xp;
// 更新下一个节点的前一个节点
if (xpn != null)
((TreeNode<K,V>)xpn).prev = x;
// 平衡树并将根节点移动到数组的前面
moveRootToFront(tab, balanceInsertion(root, x));
// 返回插入成功
return null;
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
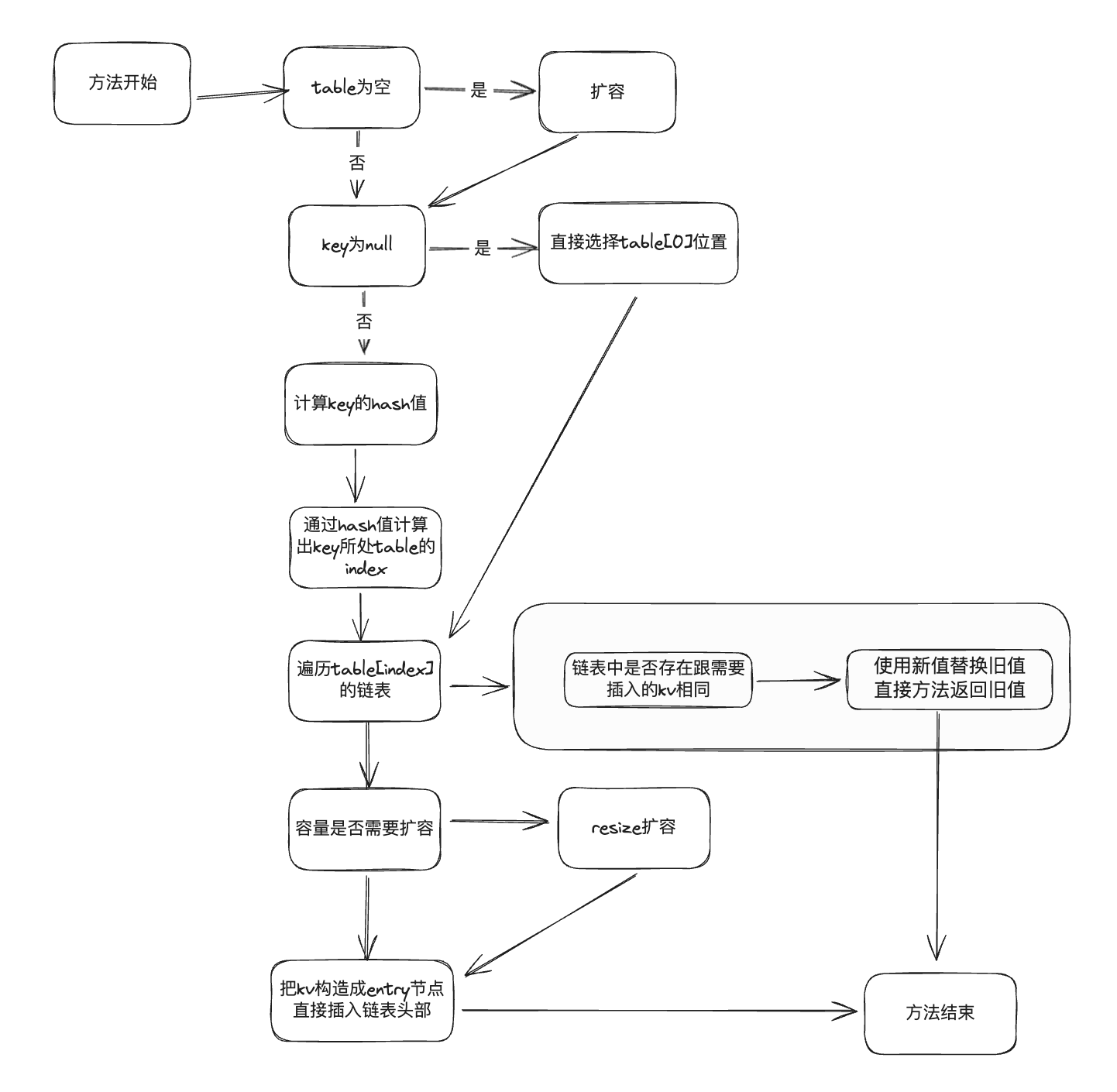
上面大家看了源码后可能还会比较混乱,可以多看几遍,这里我给大家简单梳理下,画了个流程图
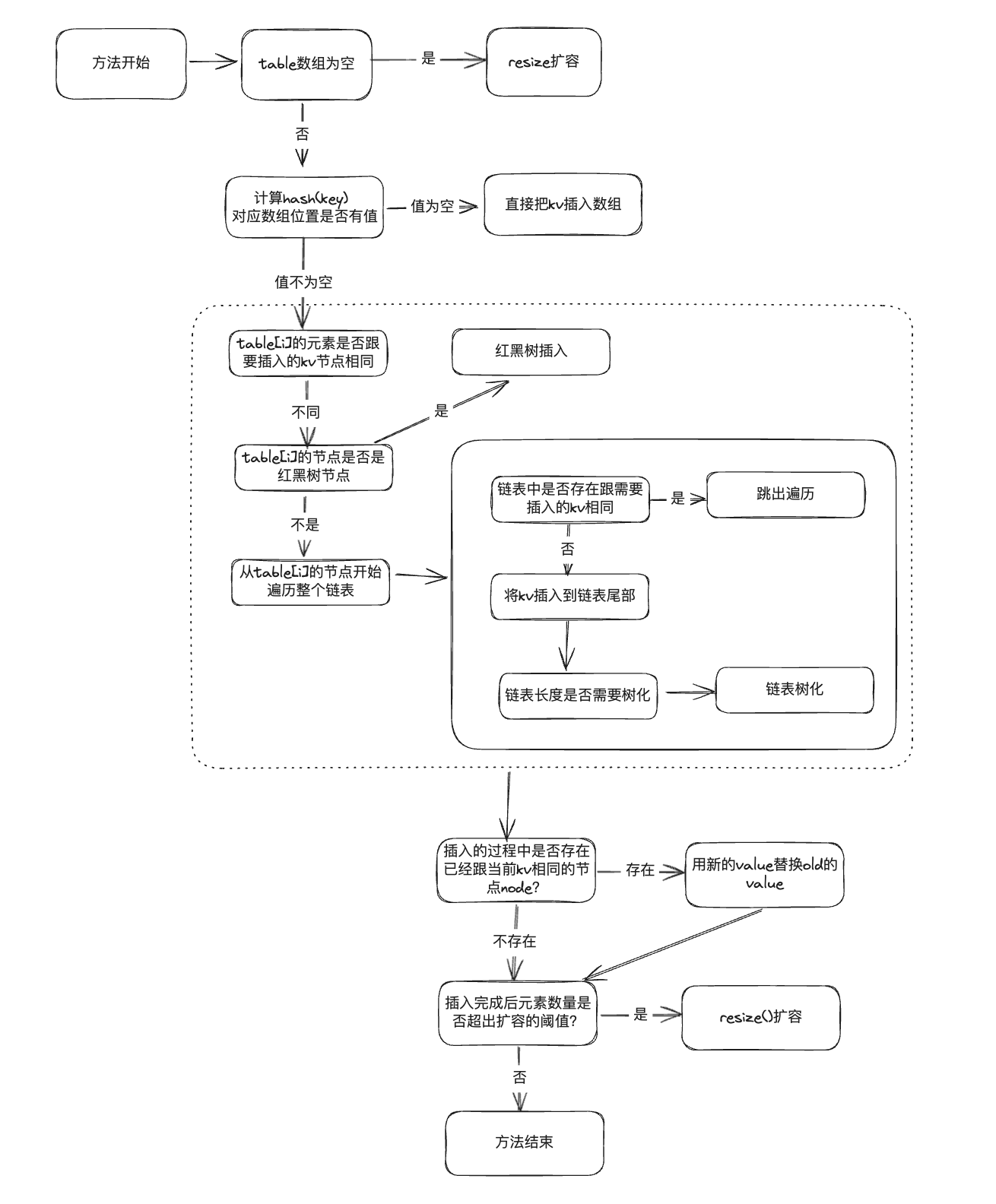
# JDK1.7
JDK1.7的put代码相对会简单很多,我们可以看下JDK1.7的源码
/**
* 默认初始容量 - 必须是2的幂。
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // 即16
/**
* 最大容量,如果在构造函数中指定了更高的值,则使用该值。
* 必须是2的幂且小于等于1<<30。
*/
static final int MAXIMUM_CAPACITY = 1 << 30;
/**
* 默认负载因子。
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
/**
* 当表未扩充时,用于共享的空表实例,为了减少空HashMap创建过多的对象
*/
static final Entry<?,?>[] EMPTY_TABLE = {};
/**
* 实际存储数据的table
*/
transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;
/**
* 将键值对添加到HashMap中。
* 如果键已存在,则更新对应的值,并返回旧值;如果键不存在,则添加新的键值对。
*
* @param key 要添加或更新的键
* @param value 要添加或更新的值
* @return 如果键已存在,则返回旧值;如果键不存在,则返回null
*/
public V put(K key, V value) {
// 如果table为空(还未存储过数据),直接扩容
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
// put null的key
if (key == null)
return putForNullKey(value);
// 计算键的哈希值,并找到表中对应的索引位置。
int hash = hash(key);
int i = indexFor(hash, table.length);
// 遍历索引位置上的链表,查找是否已存在相同的键。
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
// 如果找到相同的键,则更新值并返回旧值。
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
// 如果未找到相同的键,则将新的键值对添加到链表中。
modCount++;
addEntry(hash, key, value, i);
return null;
}
/**
* 将键为null的键值对添加到HashMap中。
* 如果已存在键为null的键值对,则更新对应的值,并返回旧值;如果不存在,则添加新的键值对。
*
* @param value 要添加或更新的值
* @return 如果已存在键为null的键值对,则返回旧值;如果不存在,则返回null
*/
private V putForNullKey(V value) {
// 遍历索引为0的位置上的链表,查找是否已存在null键的条目。
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null) {
// 如果找到null键的条目,则更新值并返回旧值。
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
// 如果未找到null键的条目,则将新的键值对添加到链表中。
modCount++;
addEntry(0, null, value, 0);
return null;
}
/**
* 添加键值对到指定索引位置的链表中。
* 如果表的大小超过阈值且桶不为空,则进行扩容。
*
* @param hash 键的哈希值
* @param key 键
* @param value 值
* @param bucketIndex 指定的索引位置
*/
void addEntry(int hash, K key, V value, int bucketIndex) {
// 如果大小(size)超过阈值(threshold)且桶不为空,则调用resize方法进行扩容。
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
// 创建新的条目,并将其添加到指定索引位置的链表中。
createEntry(hash, key, value, bucketIndex);
}
/**
* 创建键值对的条目,并添加到指定索引位置的链表中。
*
* @param hash 键的哈希值
* @param key 键
* @param value 值
* @param bucketIndex 指定的索引位置
*/
void createEntry(int hash, K key, V value, int bucketIndex) {
//头插法,参考Entry的构造器
//取出table[bucketIndex]中元素,也就是链表中的头部元素位置
Entry<K,V> e = table[bucketIndex];
//创建一个新的entry,然后直接指定新的entry的next是原来的头元素(头插法)
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}
/**
* 链表类定义
*/
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
int hash;
/**
* Creates new entry.
*/
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
对于1.7的put方法,同样画图如下:
# get方法
# JDK1.8
我们继续看JDK1.8中的HashMap的get方法
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
/**
*
* @param hash 键的哈希值
* @param key 键
* @return 节点,如果没有则返回null
*/
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; // 数组引用
Node<K,V> first, e; // first表示索引位置的第一个节点,e表示当前节点
int n; // 数组长度
K k; // 键对象
// 如果数组不为空且长度大于0,并且索引位置的第一个节点不为空
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
// 检查第一个节点是否就是要查找的节点
if (first.hash == hash &&
((k = first.key) == key || (key != null && key.equals(k))))
return first;
// 遍历后续节点
if ((e = first.next) != null) {
// 如果节点是树节点,则调用树节点的getTreeNode方法进行查找
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
// 遍历链表中的节点,查找匹配的节点
do {
// e.hash == hash 为了避免扩容的时候,其实找到的桶的hash值其实已经变了,比如都是table[0],但是在size=16和size=32的时候 其实hash值是不同的
//(k = e.key) == key 如果链表上对应的对象跟要找的key其实是一个对象,那直接不用再比较值了,肯定value是相同的
//key != null && key.equals(k),key != null主要避免key是null,拿来equals会报错,equals比较 value是否相同
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
//找不到对应的key则返回null
return null;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
# JDK1.7
jdk1.7的get()方法的源码相对来说要简单很多
/**
* jdk1.7中链表对应的数据结构,可以看出是个单链表
*/
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
int hash;
/**
* 构造函数在创建的时候直接指定了next是哪个entry,相当于直接放到了链表之中!!
*/
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
}
/**
* 根据键获取对应的值。
*
* @param key 要查找的键
* @return 如果键存在,则返回对应的值;否则返回null
*/
public V get(Object key) {
//单独处理key=null的情况
if (key == null)
return getForNullKey();
// 如果键不为null,直接获取对应的entry
Entry<K, V> entry = getEntry(key);
//如果找到entry(相当于在HashMap中存在相同的key) 则返回对应entry的value
return null == entry ? null : entry.getValue();
}
/**
* 获取键为null的值。
*
* @return 如果大小为0,则返回null;否则返回键为null的值
*/
private V getForNullKey() {
//map中没有数据 直接返回null
if (size == 0) {
return null;
}
// 遍历链表,查找键为null的Entry
// 参考jdk1.7put的源码可以知道,在key为null的时候直接是put到了table[0]位置的链表上面
for (Entry<K, V> e = table[0]; e != null; e = e.next) {
// 如果找到键为null的Entry,返回对应的值
if (e.key == null)
return e.value;
}
// 如果没有找到键为null的Entry,返回null
return null;
}
/**
* 根据键获取对应的Entry。
*
* @param key 要查找的键
* @return 如果键存在,则返回对应的Entry;否则返回null
*/
final Entry<K, V> getEntry(Object key) {
//map中没有数据 直接返回null
if (size == 0) {
return null;
}
// 计算键的哈希值
int hash = (key == null) ? 0 : hash(key);
// 计算哈希值在table中的索引位置index
int index = indexFor(hash, table.length);
// 遍历对应的链表,查找匹配的Entry
for (Entry<K, V> e = table[index]; e != null; e = e.next) {
Object k;
// 如果找到匹配的Entry,返回该Entry
// e.hash == hash 为了避免扩容的时候,其实找到的桶的hash值其实已经变了,比如都是table[0],但是在size=16和size=32的时候 其实hash值是不同的
//(k = e.key) == key 如果链表上对应的对象跟要找的key其实是一个对象,那直接不用再比较值了,肯定value是相同的
//key != null && key.equals(k),key != null主要避免key是null,拿来equals会报错,equals比较 value是否相同
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
// 如果没有找到匹配的Entry,返回null
return null;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
# resize(扩容)方法
# JDK1.8
在HashMap中元素数量增长到超出阈值的时候则会触发扩容方法,大家应该尽量避免触发resize方法,因为resize方法的本质是创建一个更大的table数组,然后把原有的所有元素一个一个的遍历迁移过去。所以在使用HashMap的时候需要尽量确定大小,从而避免扩容
/**
* 调整HashMap的大小。
*
* @return 调整大小后的新数组
*/
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table; // 旧数组
int oldCap = (oldTab == null) ? 0 : oldTab.length; // 旧容量
int oldThr = threshold; // 旧阈值
int newCap, newThr = 0; // 新容量和新阈值
// 如果旧容量大于0
if (oldCap > 0) {
// 如果旧容量已经达到最大容量,则将阈值设置为最大整数,直接返回旧数组
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
// 如果新容量小于最大容量 && 旧容量大于等于默认初始容量
// 则将新容量设置为旧容量的两倍,阈值设置为旧阈值的两倍
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // 阈值翻倍
}
// 如果旧阈值大于0,则将新容量设置为旧阈值(初始容量是放在阈值中的)
else if (oldThr > 0)
newCap = oldThr;
// 否则,使用默认初始容量和默认负载因子计算新容量和新阈值
else {
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
// 如果新阈值为0,则根据新容量和负载因子计算新阈值
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr; // 更新阈值
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap]; // 创建新数组
table = newTab; // 更新数组引用
// 如果旧数组不为空
if (oldTab != null) {
// 遍历旧数组中的每个位置,然后把旧数组的所有节点全部迁移到新的数组中!!!!
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null; // 清空旧数组的位置
// 如果节点没有后续节点
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e; // 直接放入新数组对应的位置
// 如果节点是树节点
else if (e instanceof TreeNode)
// 分裂树节点,这里不做重点介绍,感兴趣的自己debug分析
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // 链表扩容
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
//下面讲解
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
// 如果低位链表不为空,则将其放入新数组对应的位置
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
// 如果高位链表不为空,则将其放入新数组对应的位置
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab; // 返回调整大小后的新数组
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
jdk1.8中比较难理解的就是链表扩容部分,即
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
//下面讲解
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
// 如果低位链表不为空,则将其放入新数组对应的位置
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
// 如果高位链表不为空,则将其放入新数组对应的位置
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
看懂这里的代码需要先看下前面讲解hash()方法的原理,在理解hash()方法的基础上,最难理解的部分就是这个判断
if ((e.hash & oldCap) == 0)
下面我画图来解释这个代码,看过hash()方法原理介绍可以知道,在介绍的过程中我们随便编造了一个key的hashCode,并且假设了HashMap的初始化容量位16,即下图
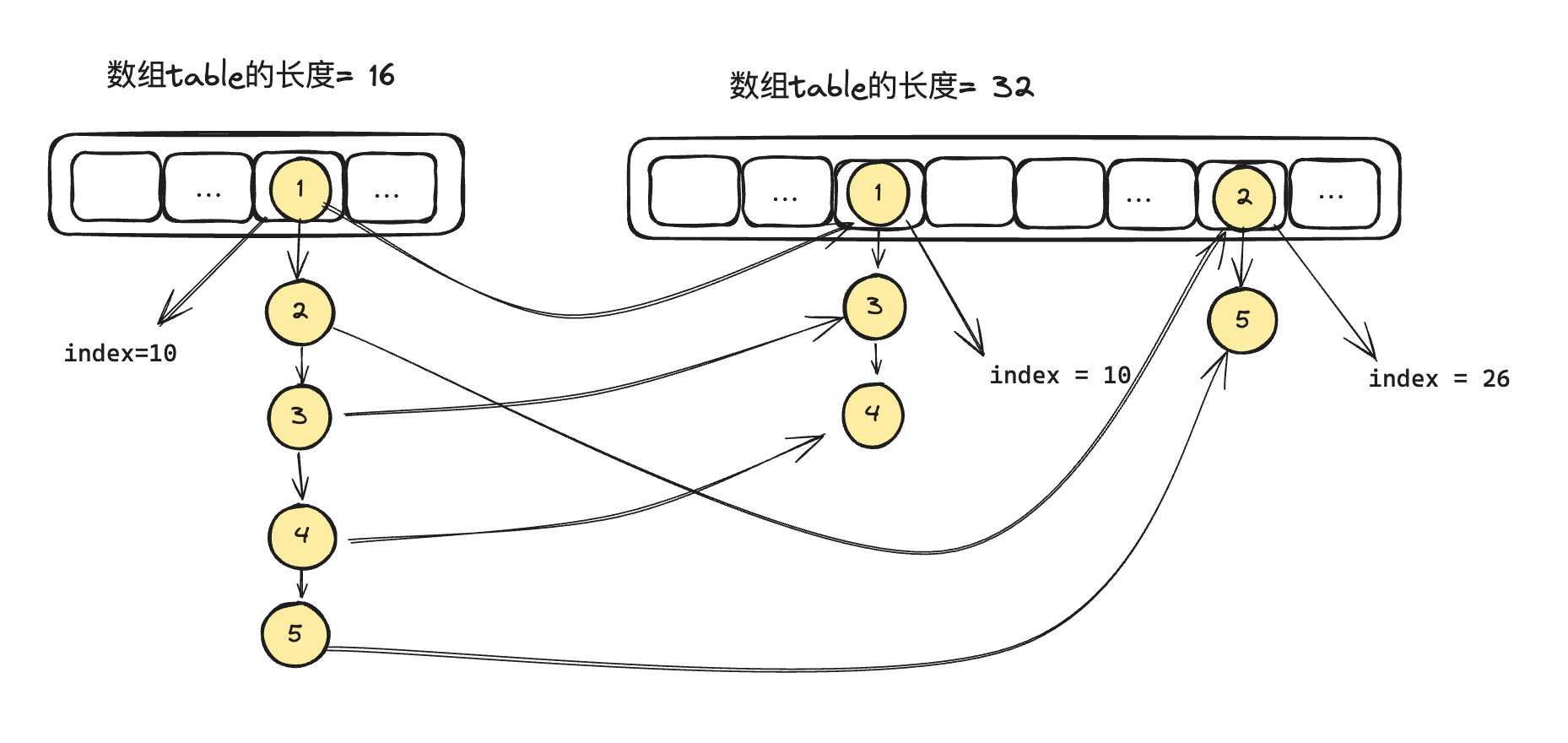
假设还有key2,key3的情况下,以及HashMap容量是16,32,64,128的情况下,我们看下 (n-1) & hash的计算结果

可以看到对于 hash(key) 值不变的情况下,扩容对于最后求index的变化如下
| Key\n | 16 | 32(旧n=16) | 64(旧n=32) | 128(旧n=64) |
|---|---|---|---|---|
| Key1的index | 10 | 26 | 26 | 90 |
| Key2的index | 1 | 1 | 1 | 1 |
| Key3的index | 9 | 26 | 57 | 121 |
可以看出(其实可以有完整的证明)对于一个key的index,随着扩容有两种变化方式,即
- 新的index = 旧的index
- 新的Index = 旧的index + 旧的n(即扩容前的容量)
所以对应代码的解释就是, 一个任意的key,扩容前后所处的table的index的变化可能是原位置,或者 原位置+旧的table容量
现在我们再来理解resize中的代码判断
//这里我们拿 key1 从HashMap的容量16 扩容到32来举例说明
//e.hash值是不变的是 1111 0000 1111 0000 0000 0000 0101 1010
//而15的二进制是 0000 0000 0000 0000 0000 0000 0000 1111
//而31的二进制是 0000 0000 0000 0000 0000 0000 0001 1111
//可以看到最终key1的index从10变成了26 是因为最终计算多了一位 1,即
//从 0000 0000 0000 0000 0000 0000 0000 1010
//变成了 0000 0000 0000 0000 0000 0000 0001 1010
//而多出来的这一位1 正是因为 15变成31的过程中多了一位1
//所以 最终可以直接 拿key的直接和以下数字 & 与运算后判断即可
// 0000 0000 0000 0000 0000 0000 0001 0000
// 而这个值正好是新的容量的一半,或者说是旧的容量 即 oldCap
// 对应代码的实现正是 e.hash & oldCap == 1 或者 e.hash & oldCap == 0
// == 0 的时候代表 新扩容后的key的index不变还是原位置,
/// == 1表示新扩容后的index = 现在的index + oldCap
if ((e.hash & oldCap) == 0)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
以上我们终于解释清楚了e.hash & oldCap的含义,现在我们继续来解释下扩容部分的其他代码
// 扩容代码核心是搞懂 loHead,loTail,hiHead,hiTail的含义
//loHead 英文写全 应该是 lowIndexHead,表示位置不变的情况下的新形成的链表的head节点
//因为从上面我们知道 扩容后的index一定是 大于等于 现在的index的,所以起名的时候 用low和high区分 (我自己的猜测)
Node<K,V> loHead = null,
//lowIndexTail ,扩容后保持不变index位置上形成的新的链表的tail节点(尾结点)
loTail = null;
//highIndexHead , 扩容后增长的新的index位置上的链表的head节点
Node<K,V> hiHead = null,
//highIndexTail ,扩容后增长的新的index位置上的形成的链表的tail节点(尾结点)
hiTail = null;
Node<K,V> next;
do {
next = e.next;
//key通过扩容后新的位置保持不变
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
//key通过扩容后新的位置产生了变化 新index = 旧index + oldCap
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
// 如果低位链表不为空,则将其放入新数组对应的位置
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
// 如果高位链表不为空,则将其放入新数组对应的位置
if (hiTail != null) {
hiTail.next = null;
//新index = 旧index(j) + oldCap
newTab[j + oldCap] = hiHead;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
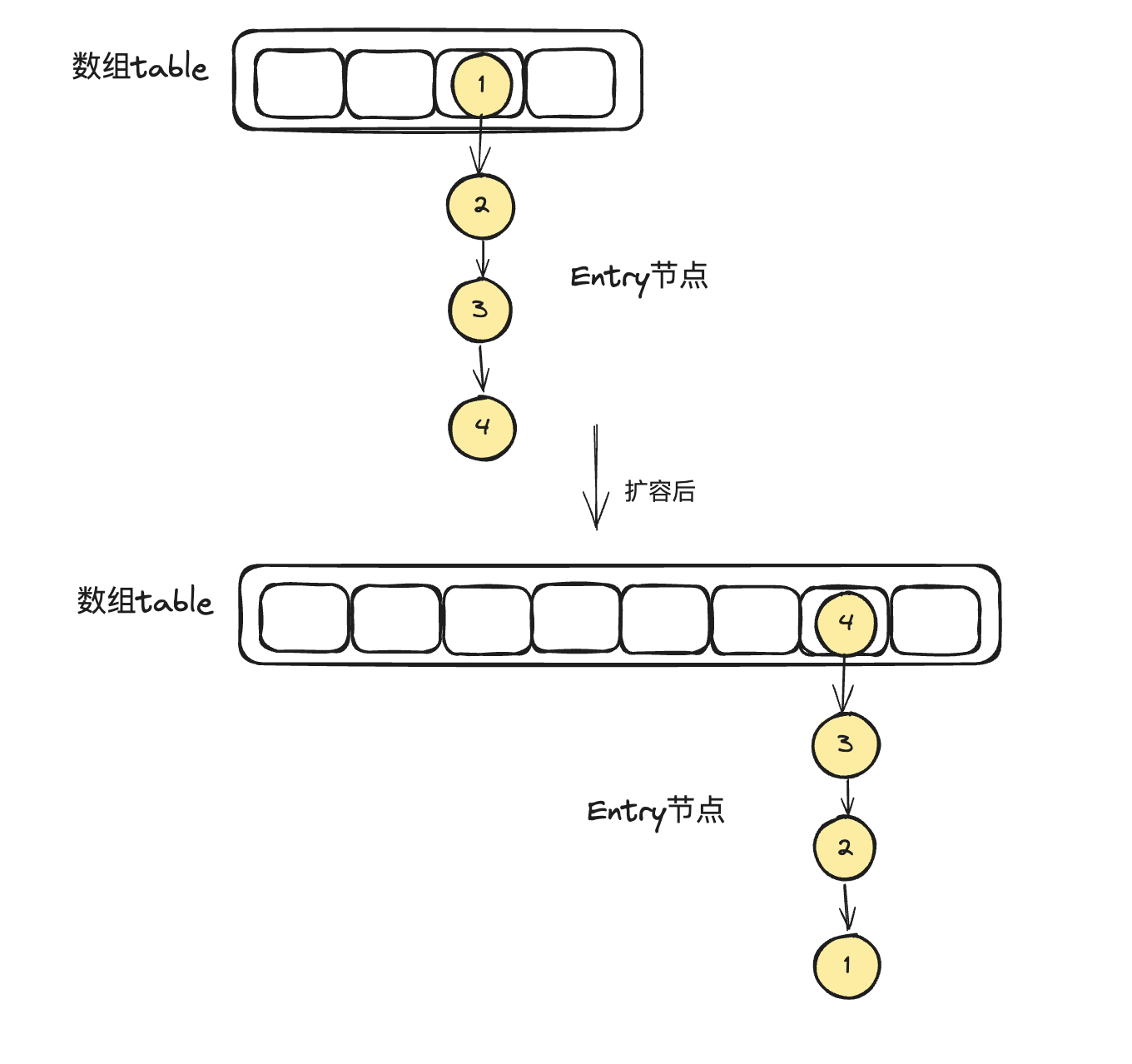
while循环遍历的过程大家可以自己debug代码,我这里就详细解释了,但是画个大概得扩容过程给大家看
可以看到在jdk1.8中,一个链表扩容前后 链表中节点的相对位置保持不变,比如 1->3->4 和 2->5 依旧遵守了原有链表 1->2->3->4->5的顺序,这个和jdk1.7有比较大的不同。
# JDK1.7
对比jdk1.8的扩容方法, 1.7就简单了非常多
/**
* 调整HashMap的容量。
*
* @param newCapacity 新的容量
*/
void resize(int newCapacity) {
Entry[] oldTable = table;
// 获取旧的容量
int oldCapacity = oldTable.length;
// 如果旧的容量已经达到最大值
if (oldCapacity == MAXIMUM_CAPACITY) {
// 将阈值设置为Integer的最大值,直接放弃扩容
threshold = Integer.MAX_VALUE;
return;
}
// 创建新的表,容量为newCapacity(注意此时 表是空的)
Entry[] newTable = new Entry[newCapacity];
// 将旧的表的内容转移到新的表
transfer(newTable, initHashSeedAsNeeded(newCapacity));
// 将新的表赋值给table
table = newTable;
// 更新阈值,阈值为Min(新的容量与负载因子之积,但不能超过最大容量+1)
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
/**
* 将旧的表的内容转移到新的表。
*
* @param newTable 新的表
* @param rehash 如果需要重新计算哈希值,为true;否则为false
*/
void transfer(Entry[] newTable, boolean rehash) {
// 获取新的容量
int newCapacity = newTable.length;
// 遍历旧的表
for (Entry<K,V> e : table) {
// 如果当前Entry不为null
while(null != e) {
//提前获取下next元素
Entry<K,V> next = e.next;
if (rehash) {
// 计算哈希值,如果键为null,哈希值为0;否则,调用hash()计算哈希值
e.hash = null == e.key ? 0 : hash(e.key);
}
// 计算哈希值在新表中的索引位置
int i = indexFor(e.hash, newCapacity);
//重要!!!
//让当前元素的next指向 newTable[i]位置上的链表的第一个元素
e.next = newTable[i];
// 把e设置成newTable[i]上的链表的第一个元素
newTable[i] = e;
// 把next复制给e,相当于重复遍历下一个元素了
e = next;
//51-53行可以看出 jdk1.7扩容的时候使用的是链表的头插法!!
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
51-53行可以看出 jdk1.7扩容的时候使用的是链表的头插法,这里可以看出,如果一个链表原始顺序是 1->2 ->3 ->4 ,假设扩容后还在同一个链表上,那扩容后的顺序就是 4 -> 3 ->2 -> 1
# 常见面试问题
# 1.什么是hash冲突?如何解决?
# hash冲突
假设hash表的大小为9(即有9个槽),现在要把一串数据存到表里:5,28,19,15,20,33,12,17,10
简单计算一下:hash(5)=5, 所以数据5应该放在hash表的第5个槽里;hash(28)=1,所以数据28应该放在hash表的第1个槽里;hash(19)=1,也就是说,数据19也应该放在hash表的第1个槽里——于是就造成了碰撞(也称为冲突,collision)。
# 如何解决hash冲突
- 开放定址法:也称再散列法,其基本思想是,当关键字key的哈希地址p=H(key)出现冲突时,以p为基础,产生另一个哈希地址p1,如果p1仍然冲突,再以p为基础,产生另一个哈希地址p2,…,直到找出一个不冲突的哈希地址pi ,将相应元素存入其中
- 再哈希法:这种方法是同时构造多个不同的哈希函数hash2,发生冲突时,再计算使用hash2(),hash() ... 直到冲突不再产生。这种方法不易产生聚集,但增加了计算时间。
- 链地址法:HashMap采用的解决办法,冲突的值使用链表顺序组装
- 公共缓冲区:将哈希表分为基本表和溢出表两部分,凡是和基本表发生冲突的元素,一律填入溢出表。
# 2.HashMap有什么特性
HashMap成为一种常用的数据结构,适用于需要快速查找和插入键值对的场景。
键值对存储:HashMap是基于键值对(Key-Value)的数据结构,每个键在HashMap中是唯一的
高效的查找和插入:HashMap使用哈希表(Hash Table)实现,通过将key转换为hashcode来快速查找和插入元素。哈希表允许在平均情况下以常数时间复杂度(O(1) 进行这些操作。
动态调整大小:HashMap具有自动调整大小的能力。当元素数量超过阈值时,HashMap会自动进行扩容,从而提供更好的性能。
无序性:HashMap中的元素没有固定的顺序。无法保证读取顺序与插入顺序相同。
允许空键和空值:HashMap允许使用null作为键和值。
线程不安全:HashMap是非线程安全的,如果需要在多线程环境中使用HashMap,可以使用ConcurrentHashMap或对HashMap进行同步操作
# 3.HashMap线程安全吗?存在什么问题吗 ?如何解决 ?
HashMap并不是线程安全的,在并发环境中使用HashMap会导致以下问题
- HahMap在jdk1.7扩容的时候容易形成循环链表,导致get操作一直循环遍历,cpu使用率飙升
- 多线程put的时候size个数和真正的个数不一样
- 多线程put的时候,有概率会覆盖上一个put操作的值
- 多线程put和get的时候可能触发并发异常
- get操作的时候,同时HashMap在扩容,get的数据分桶变了,从而导致get不到数据
# 如何解决HashMap的线程安全问题?
- 使用HashMap的安全类HashTable 或者 ConcurrentHashMap
- 使用
Collections.synchronizedMap()方法给HashMap加同步锁 - 想办法把并发操作的HashMap变成每个线程独享的HashMap,比如ThreadLocal技术
所以整体其实就2种思路,这也是通用的解决并发问题的大致思路
- 加互斥锁
- 不共享HashMap,每个线程独有
# 4.为什么HashMap的容量一定是2^n ?
HashMap中大量使用了hash()方法,hash()方法中又是通过位移来快速运算(参考上面介绍的 hash()方法的介绍),而 位运算 要比 % 取模运算效率高很多,因为直接基于二进制进行运算,所以为了保持高性能,HashMap的容量必须是2^n 来保障hash()方法计算的效率。
# 5.HashMap中的modCount有什么用?
先看官方的解释
/**
* The number of times this HashMap has been structurally modified
* Structural modifications are those that change the number of mappings in
* the HashMap or otherwise modify its internal structure (e.g.,
* rehash). This field is used to make iterators on Collection-views of
* the HashMap fail-fast. (See ConcurrentModificationException).
*/
transient int modCount;
2
3
4
5
6
7
8
9
简单来说就是,modCount是用来记录 HashMap中元素修改的次数,同时这个字段用来在遍历的时候保障该集合的 fail-fast机制。
# 什么是fail-fast? fail-safe?
fail-fast如表面意思 快速失败,是一种系统设计的理念,简单来说就是 代码出了问题需要立刻停止,当然 fail-safe就和fail-fast相反,除了问题也可以继续往下执行。
fail-fast机制本质来说是保障系统可以快速感知问题的一种手段,举例比如,计算机运算过程中的 除0异常,在我们常用的集合中大部分都内置了参数 modCount来实现fail-fast机制,也就是在集合遍历的过程中禁止添加和移除元素(因为这样可能会导致遍历代码的异常)。
但是Java中也存在一些fail-safe机制的集合,比如 juc包(java.util.concurrent)下的所有集合都是 fail-safe的(juc包下集合源码我们后续介绍)
# 6.什么是负载因子? 默认值是多少?为什么要这样设置?
负载因子的意思是当 HashMap中 元素个数 > 负载因子 * 预期容量 则触发扩容,HashMap默认负载因子是0.75
# 负载因子存在的意义
如果不存在负载因子那么HashMap则在table满了才会触发扩容或者更多元素才触发,但是这样存在hash冲突的概率就会提高,所以可能会导致性能下降。同时如果此时HashMap中元素很多,那就需要计算每个值的hashcode再重新分配桶,这样耗时反而会增加的更厉害。极端情况如果数据产生了偏斜,table某个位置链表长度非常长,那查询和插入的耗时是会极大的增加。
官方文档中原话如下:
* <p>As a general rule, the default load factor (.75) offers a good * tradeoff between time and space costs. Higher values decrease the * space overhead but increase the lookup cost (reflected in most of * the operations of the <tt>HashMap</tt> class, including * <tt>get</tt> and <tt>put</tt>). 一般来说,默认的load factor 0.75提供了一个比较好的时间和空间的平衡。更高的值(大于0.75)降低了空间的消耗,但是增加了查询操作的耗时(对应HashMap的 get和put操作)1
2
3
4
5
6
7
总结:0.75是一个比较好的时间复杂度和空间复杂度的权衡值,关于这个数字的数学思考(可能):https://stackoverflow.com/questions/10901752/what-is-the-significance-of-load-factor-in-hashmap
# 7.HashMap JDK1.8有什么改动吗?为什么要这样改?
在JDK1.8中主要对HashMap的put方法进行了修改,在jdk1.7的基础上,table中一个节点对应的链表数量大于等于8则会把链表修改成红黑树,当红黑树中节点数量小于等于6的时候又会重新修改为链表。
# 为什么要这样修改?
HashMap解决hash冲突使用的方法是拉链法,这样在极端情况下会存在单个链表数据过长的问题,在遇到极端情况,一个长度为n的链表(n很大),HashMap调用get方法的时候查询时间复杂度无线接近O(n),这种情况是不能接受的,所以需要使用一个新的数据结构来解决极端情况。
# 为什么是红黑树?
简单概述:红黑树是现有的数据结构中最好平衡HashMap中的get和put操作的数据结构。
链表:在极端情况下,查找时间复杂度是O(N)
二叉查找树(BST):
参考:https://www.runoob.com/data-structures/binary-search-tree.html
在极端条件下,二叉查找树会退化成链表,查找效率O(n)
二叉平衡树(AVL):
参考:https://zhuanlan.zhihu.com/p/56066942
AVL树在查询上可以保证效率O(logN),但是每次插入删除数据都需要左旋或者右旋来保持平衡,比较耗时,所以对于修改比较多的场景非常不合适。
红黑树(Red Black Tree)
参考:https://zhuanlan.zhihu.com/p/273829162
AVL是严格的平衡树,因此在增加或者删除节点的时候,根据不同情况,旋转的次数比红黑树要多;红黑树是用非严格的平衡来换取增删节点时候旋转次数的降低开销; 所以简单说,如果你的应用中,搜索的次数远远大于插入和删除,那么选择AVL树, 如果搜索,插入删除次数几乎差不多,应选择红黑树。
所以综合下来,红黑树数据结构最能应对HashMap的使用场景包括大量的查询和插入修改
# 为什么链表数据是8的时候才转红黑树?
* Because TreeNodes are about twice the size of regular nodes, we * use them only when bins contain enough nodes to warrant use * (see TREEIFY_THRESHOLD). And when they become too small (due to * removal or resizing) they are converted back to plain bins. In * usages with well-distributed user hashCodes, tree bins are * rarely used. Ideally, under random hashCodes, the frequency of * nodes in bins follows a Poisson distribution * (http://en.wikipedia.org/wiki/Poisson_distribution) with a * parameter of about 0.5 on average for the default resizing * threshold of 0.75, although with a large variance because of * resizing granularity. Ignoring variance, the expected * occurrences of list size k are (exp(-0.5) * pow(0.5, k) / * factorial(k)). The first values are: * * 0: 0.60653066 * 1: 0.30326533 * 2: 0.07581633 * 3: 0.01263606 * 4: 0.00157952 * 5: 0.00015795 * 6: 0.00001316 * 7: 0.00000094 * 8: 0.00000006 * more: less than 1 in ten million 由于 TreeNodes 的大小大约是普通节点的两倍,因此我们 只有包含足够多的节点时,我们才会使用它们(TREEIFY_THRESHOLD)。 当它们变得太小时(由于移除或调整大小)时,它们就会被转换回普通链表。 在随机散列的情况下,节点的数量分布遵循泊松分布 (http://en.wikipedia.org/wiki/Poisson_distribution) 对于默认的扩容阈值0.75来说,平均情况下,参数大约为0.5 尽管由于扩容粒度的原因,存在较大的方差。 忽略方差的影响,列表大小为k的预期出现次数为 (exp(-0.5) * pow(0.5, k) / factorial(k)) 值如下: 0: 0.60653066 1: 0.30326533 2: 0.07581633 3: 0.01263606 4: 0.00157952 5: 0.00015795 6: 0.00001316 7: 0.00000094 8: 0.00000006 更多(>8): 小于千万分之一1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
总结:
- TreeNodes的大小是普通链表Node大小的两倍(占用内存),所以只能在一定情况下再从链表node转成TreeNode
- 在遵循随机hash的情况下,某个节点数量的大小遵循泊松分布,数量等于8的概率约为0.00000006,意思就是节点大于等于8的概率非常非常小,所以认为8是一个比较合理的数字(有数学依据的,并不是拍脑袋的)
# 为什么红黑树数量为6的时候又转回链表?
- 链表在比较少的节点情况下插入性能是优于红黑树的,占用内存空间也是优于红黑树的
- 如果在小于8的时候再转回去存在的问题是:如果频繁的修改导致节点数量一直在8上下那么会导致频繁的树化,从而导致更大的效率降低
- 6是一个经验值,在绝大部分情况下表现很好
- 总体来说就是在 空间和时间复杂度寻找一个平衡点
# 8.HashMap扩容会有什么问题 ?
在jdk1.7中扩容会形成环形链表,也就是死循环,当再有线程调用get()方法时,如果正好key在该桶并且key不存在则会导致死循环,cpu使用率飙升100%,最终导致应用无法对外服务,下面我们画图来解释下这个过程,以下是JDK1.7的扩容代码
JDK1.7 的扩容代码
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
//这里需要注意 newTable是不共享的,也就是每个线程都有自己的newTable
Entry[] newTable = new Entry[newCapacity];
transfer(newTable, initHashSeedAsNeeded(newCapacity));
//多线程执行这里会导致数据丢失
table = newTable;
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(e != null ){
//提前获取下next元素
Entry<K,V> next = e.next;
//忽略其他代码
//把e的next指向 新的地址i上的元素 table[i]
e.next = newTable[i];
// 把e设置成newTable[i]上的链表的第一个元素
newTable[i] = e;
// 把next复制给e,相当于重复遍历下一个元素了
e = next;
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
# 环形链表
我们都知道在单线程下 HashMap扩容过程如图(假设我们只有两个元素,并且忽略扩容后数组大小并且扩容后2个元素依旧在同一个桶上)
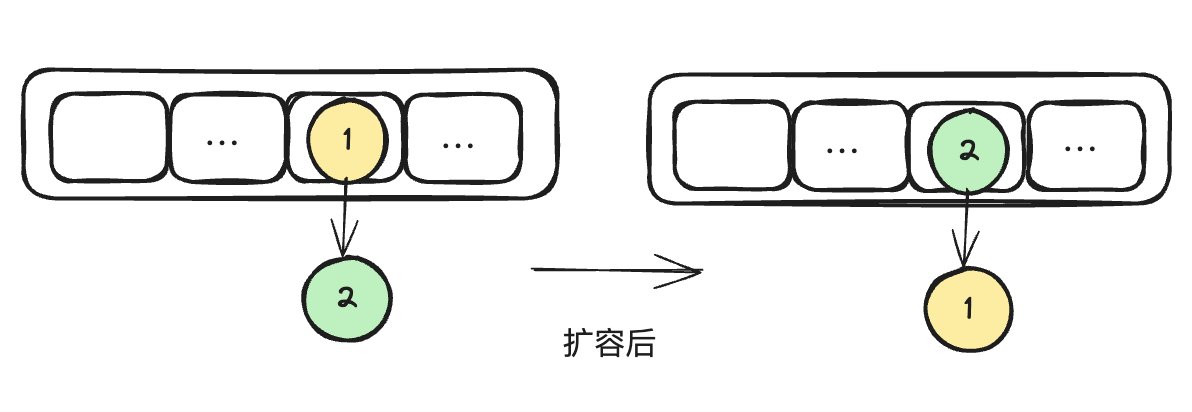
但是如果有多线程同时执行上面扩容的代码则会出现问题。
假设有t1和t2两个线程同时在执行上面的扩容代码。
- t1在执行
Entry<K,V> next = e.next;代码的时候cpu时间片耗尽停住
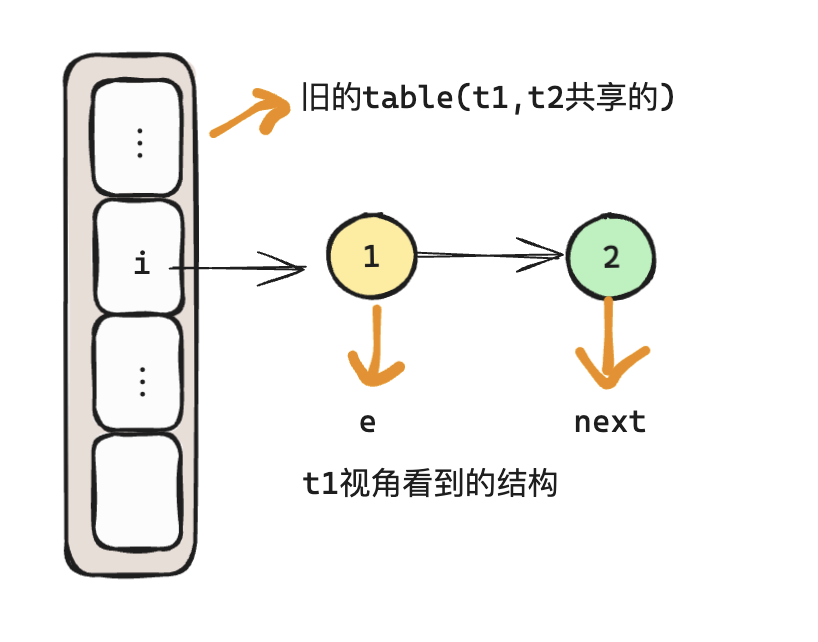
- 此时t2 执行完了全部的扩容流程,此时数据排列如下
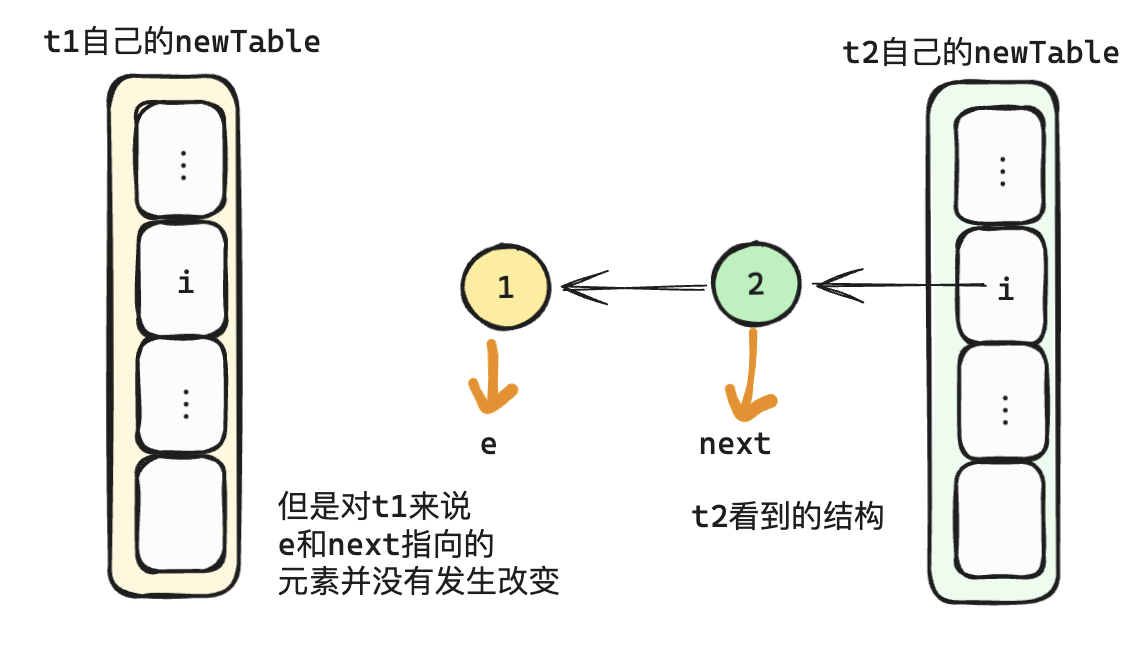
- 此时t1执行完一下代码后
//把e的next指向 新的地址i上的元素 table[i]
e.next = newTable[i];
// 把e设置成newTable[i]上的链表的第一个元素
newTable[i] = e;
// 把next复制给e,相当于重复遍历下一个元素了
e = next;
2
3
4
5
6
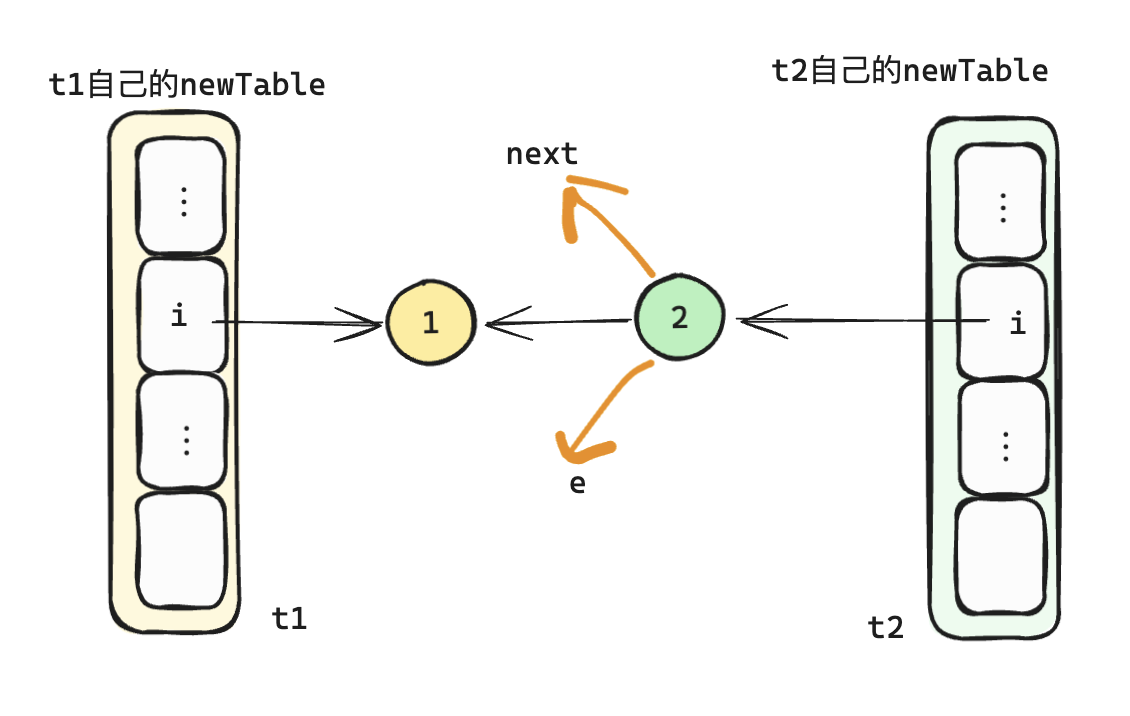
紧接着
e != null满足条件,t1进行下一次循环,执行以下代码//提前获取下next元素 Entry<K,V> next = e.next; //忽略其他代码 //把e的next指向 新的地址i上的元素 table[i] e.next = newTable[i]; // 把e设置成newTable[i]上的链表的第一个元素 newTable[i] = e; // 把next复制给e,相当于重复遍历下一个元素了 e = next;1
2
3
4
5
6
7
8
9
10
11
12
13
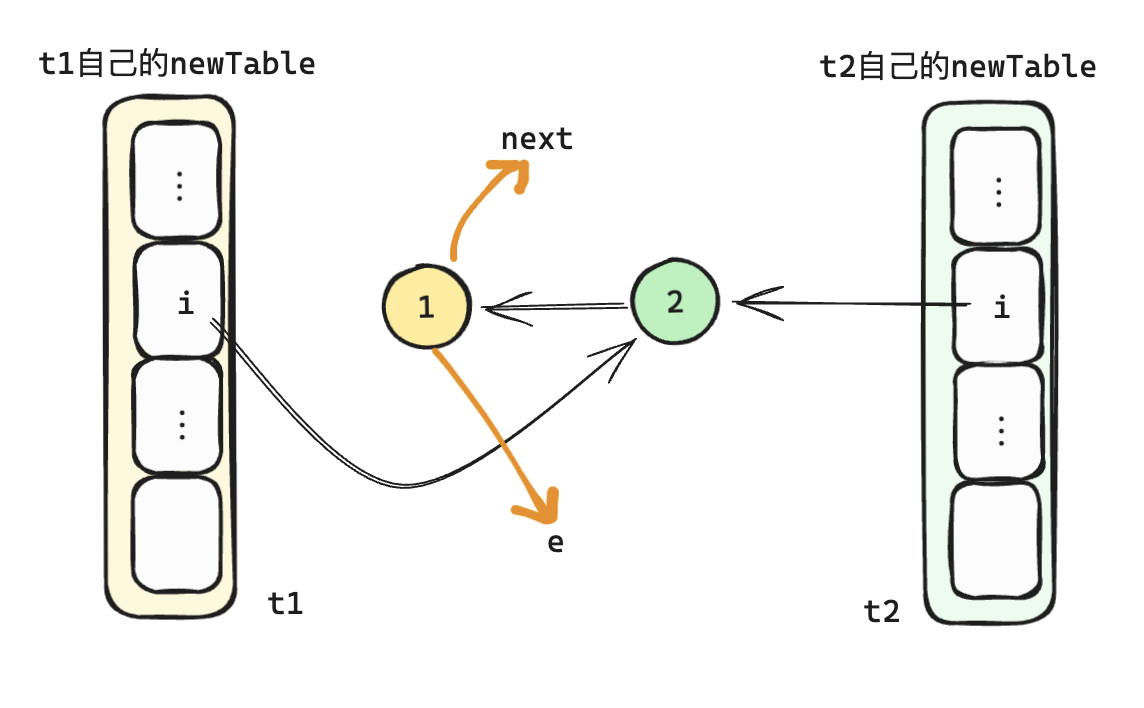
- 结束后判断
e != null依旧满足条件,t1进行下一次循环,再次执行完循环代码后
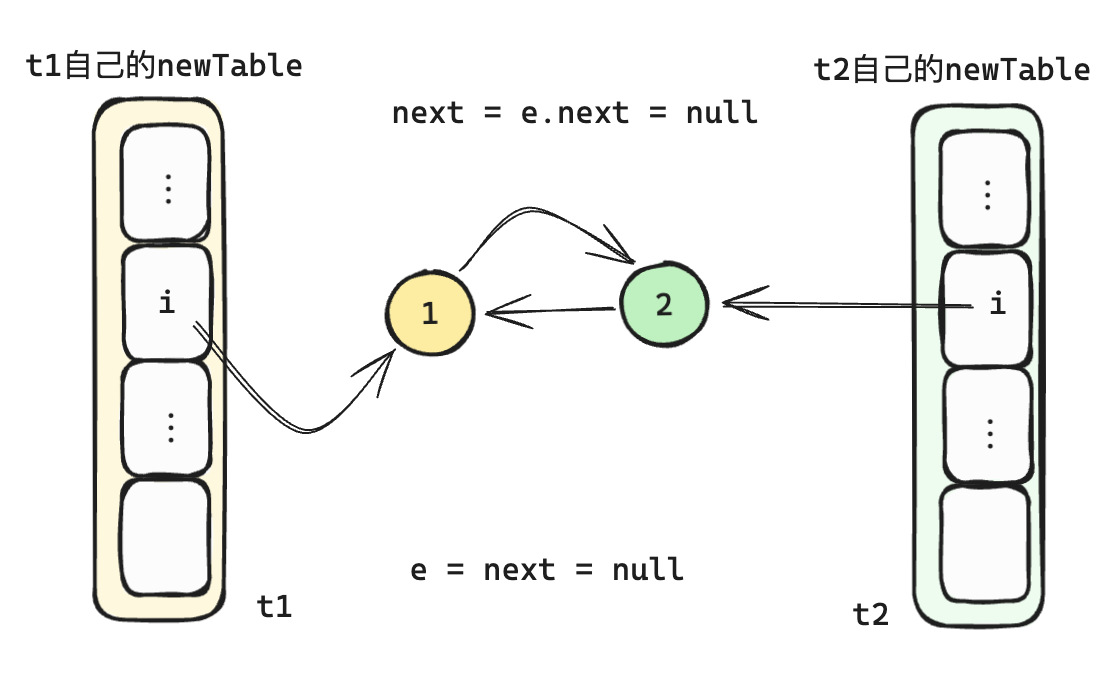
此时e == null结束扩容,但是可以看到在t1代码执行完毕后,链表已经形成了环,当下次get该桶的数据的时候则会在环形链表中不停的执行,直到CPU 飙升到100%,应用无法对外提供服务。
# 数据覆盖/丢失
JDK1.7的扩容代码
//这里需要注意 newTable是不共享的,也就是每个线程都有自己的newTable
Entry[] newTable = new Entry[newCapacity];
//实际扩容的代码,newTable会被填充数据
transfer(newTable, initHashSeedAsNeeded(newCapacity));
//多线程执行这里会导致数据丢失
table = newTable;
2
3
4
5
6
7
8
可以看到,如果有多个线程同时执行以上代码,因为newTable是每个线程私有的,table是每个线程共享的,所以在执行table = newTable;代码的时候最终只有一个线程的newTable赋值到table上,也就是其他线程扩容的数据全部丢失了,所以如果扩容后的数据并不相同,则会导致整体HashMap丢数据
# 9.HashMap容量要怎么设置才比较合理 ?
参考上面我们介绍的HashMap的构造函数以及resize过程,我们可以确认的是:在使用HashMap的过程中应该尽量避免HashMap的扩容发生,基于以上逻辑,我们在已知数据容量的前提下,可以通过指定 size,让HashMap直接初始化到指定容量,从而避免扩容,但是这里需要注意的是,你指定了初始化的initialCapacity,但是可能还是会触发扩容!下面举例来说。
假设我们需要存入的数据大小为7,使用构造函数传入7,则是
Map map = new HashMap(7);
然而通过上面的阅读我们知道,最终HashMap扩容出来的数量是8 ,即大于7的最小的2的次幂,也就是table的size=8,那么扩容的threshold则是 8 *0.75 = 6, 也就是当我们存入6个元素的时候,HashMap则会发生扩容,这个与我们期望的完全不同!!
所以正确的设置初始化的值则是
initialCapacity = (size / 0.75F) + 1
假设我们需要存入7个元素, initialCapacity = 7/0.75 +1 = 10, HashMap则会初始化成16,默认扩容的阈值 threshold = 16 * 0.75 = 12, 这样就完全不会发生扩容。
当然我们也不需要每次都这样麻烦的计算,guava库中已经给我们提供了现成的实现
public static <K extends @Nullable Object, V extends @Nullable Object>
HashMap<K, V> newHashMapWithExpectedSize(int expectedSize) {
return new HashMap<>(capacity(expectedSize));
}
static int capacity(int expectedSize) {
if (expectedSize < 3) {
checkNonnegative(expectedSize, "expectedSize");
return expectedSize + 1;
}
if (expectedSize < Ints.MAX_POWER_OF_TWO) {
// This is the calculation used in JDK8 to resize when a putAll
// happens; it seems to be the most conservative calculation we
// can make. 0.75 is the default load factor.
return (int) ((float) expectedSize / 0.75F + 1.0F);
}
return Integer.MAX_VALUE; // any large value
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18